The Craft of Multi-Agent Collaboration Design
싱글 LLM의 한계를 넘어서는 멀티에이전트 시스템(MAS)은 단순한 역할 분담이 아니라, 구조·협업·커뮤니케이션 설계를 통해 창발적 지능을 만들어내는 아키텍처다. 이 글은 토폴로지, 협업 전략, 동적 오케스트레이션, 커뮤니케이션 프로토콜 등 실제 프로덕션 환경에서 MAS를 설계할 때 필요한 핵심 기술과 트레이드오프를 구체적으로 다룬다.

AI Research Team | woojung.son
In the previous post, we examined why the structural limitations of single-LLM systems push us toward Multi-Agent Systems (MAS), how the Collaborative Scaling Law empirically validates this direction, and where Test-time Compute Scaling and Agent Scaling intersect. This time, we go one level deeper. We'll start by asking why a multi-agent system is something fundamentally different from "just a bunch of agents running in parallel"—a question best answered through the lens of emergent intelligence. From there, we'll work through the concrete design decisions every MAS architect has to make: topology, collaboration strategy, communication protocols, and evaluation.
The Limits of Single-Agent Systems (A Quick Recap)
Before we talk about collaboration, it's worth restating why we need it. The case against single-agent architectures rests on four pillars.
No parallelism. A single agent, by construction, is a sequential machine—one task has to finish before the next begins. The moment your workload demands simultaneous research, coding, and review, that sequential pipeline becomes a hard bottleneck.
Tangled state and memory. When a single agent swaps between roles inside the same conversational context, its memory and working assumptions bleed into each other. And because LLMs are autoregressive, a single bad token or a flawed premise generated early on conditions everything that follows [1]. It's not a bug you can patch around; it's baked into how the models generate.
No independent verification. Any internal critic inside a single agent is, at the end of the day, the same model grading its own homework. When the same weights look at the same context and try to second-guess themselves, what you get isn't independent review—it's rationalization. Huang et al. (ICLR 2024) made this painfully clear: intrinsic self-correction has a hard ceiling [2].
Single point of failure. If the one agent goes down—whether from a crash, a prompt injection, or a bad API call—the whole system goes dark. A multi-agent setup, by contrast, can route around damage and degrade gracefully when one component fails.
These four limitations are what push us into multi-agent territory. But before we dive into the mechanics of how agents should cooperate, there's a conceptual point worth making first—because it shapes everything that follows.
Emergent Intelligence in Multi-Agent Systems
A multi-agent system is not just "several agents in a trench coat." Once individual models cross a certain capability threshold, the most effective way to push system-level performance further stops being "make the model smarter" and starts being "figure out how to make the models work together." The gains here aren't additive—they're emergent. How agents are wired together and how they interact determines whether the system exhibits capabilities that no single agent, no matter how capable, could reach on its own.
Consider humans. Individual Homo sapiens haven't gotten dramatically smarter over the last hundred thousand years, yet human civilization has become exponentially more powerful thanks to collective intelligence and coordination [3]. Division of labor, markets, institutions, and communication infrastructure combined the capabilities of countless individuals into civilizational-scale output. The same logic maps onto AI agents: a generally capable agent hits a ceiling when it operates alone, but the moment you give it a properly orchestrated team, the system's output blows past what you'd get by summing individual contributions.
From this vantage point, a genuinely powerful AI system needs four core capabilities:
- Adaptivity — responding dynamically to a changing environment.
- Context-awareness — maintaining persistent state and memory.
- Conflict resolution — mediating between competing demands.
- Long-term planning — coordinating sequences of actions and making decisions over extended horizons.
Asking a single model to max out all four simultaneously is wildly inefficient. A multi-agent system, on the other hand, lets you distribute these capabilities across specialized agents and compose them. The research community has recently given this idea a name: the patchwork AGI hypothesis—the claim that general-intelligence-level capability may emerge first through the orchestration of complementary sub-AGI agents, rather than from a single monolithic model [4].
So how do we actually design that collaboration?
Three Paradigms of Collaboration
Agents can cooperate in broadly three ways, and the differences matter.
Rule-based collaboration is the simplest. Multiple agents tackle the same problem independently, and a majority vote decides the answer. Self-Consistency [5] is the canonical example. It's easy to implement, the behavior is predictable, and it gives you cheap gains on reasoning benchmarks. But because there's no real information exchange between agents, it hits a wall on anything that requires actual back-and-forth.
Role-based collaboration mirrors how human organizations actually work. A Product Manager, a Solution Architect, a Developer, and a QA Engineer each own a piece of the problem—this is the paradigm behind frameworks like MetaGPT [6] and ChatDev [7]. When a request like "write a product launch report with a risk assessment" comes in, an orchestrator decomposes it: research goes to the Research role, analysis goes to the Analysis role, and so on. It's the same logic as assigning work in a functional org.
Model-based collaboration is the most sophisticated of the three. Here, agents build probabilistic models of each other's intentions and states—Theory of Mind (ToM) applied to artificial agents. Think of agents predicting an opponent's strategy in a game and adapting accordingly. It's powerful in high-uncertainty environments, but the implementation complexity is no joke.
The key insight is that these paradigms aren't mutually exclusive. Within a single task, they mix and shift dynamically. Agents might start in cooperation mode, shift into competition the moment a Critic agent enters the picture, and then converge back toward a shared objective as they iterate toward a better answer. This coopetition pattern is, in our experience, the most effective shape for real production systems.
Collaboration Topology: Structure Determines Performance
Once you've picked a collaboration strategy, the next decision is how to wire the agents together.
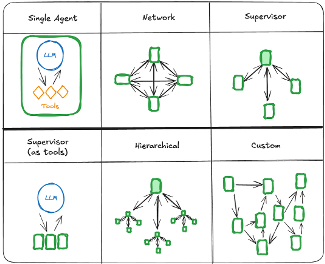
Network (peer-to-peer) topology lets every agent talk to every other agent. It's maximally flexible, but communication complexity scales as O(n²) with the number of agents. It's the right shape for brainstorming or open debate, where diverse viewpoints need to cross-pollinate freely.
Supervisor topology puts a manager agent in the middle, dispatching tasks to subordinates and collecting results. Control flow is clean and debugging is tractable, but the supervisor can become a bottleneck. LangGraph's "Supervisor-as-tools" pattern is a clever variant: the supervisor calls subordinate agents as if they were tool functions, which gives you function-like reusability.
Hierarchical topology stacks supervisors under supervisors. It's the org chart of the AI world—a good fit for large, complex systems where no single supervisor could reasonably track everything.
In practice, you almost never see these topologies in their pure form. Take the proposal-writing MAS we designed internally: a Proposal Manager sits at the top (supervised structure), but between the Solution Architect and the Pricing Agent—where technical design and cost estimates feed back into each other constantly—you get a network (swarm) structure. Supervised and swarm patterns coexist in the same system. Hybrid topology is the norm, not the exception.
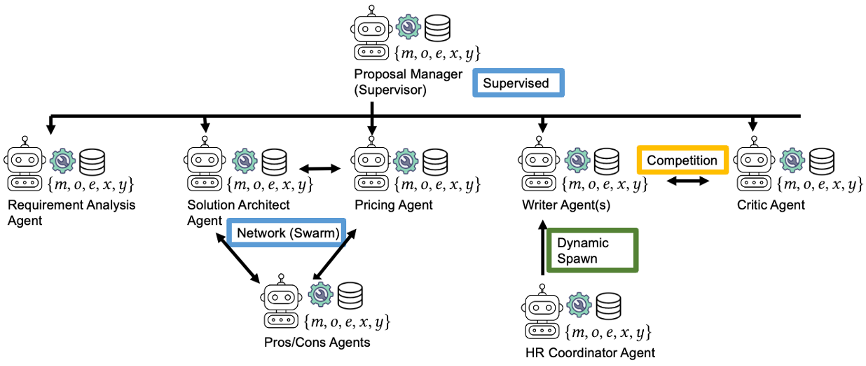
The Proposal Manager (Supervisor) oversees the system, while Solution Architect ↔ Pricing Agent form a network/swarm, Writer Agent ↔ Critic Agent sit in a competition loop, and an HR Coordinator handles dynamic spawning.
The point isn't that any one topology is objectively best. The point is that topology is a design knob you tune to the task.
Cooperation, Competition, Coopetition: 인센티브 구조의 설계
If topology is the skeleton, then the incentive structure is the nervous system.
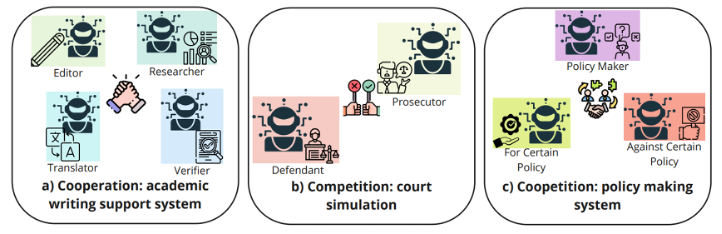
Cooperation is the case where all agents pull toward a shared goal through division of labor. An academic writing system—Editor handling structure, Researcher gathering sources, Translator localizing, Verifier checking quality—is the textbook example.
Competition puts agents in structural opposition. In a courtroom simulation, the Prosecutor tries to prove guilt while the Defendant argues innocence. Adversarial Debate structures like this are genuinely effective at raising argument quality, and they're increasingly used to catch hallucinations: a Writer drafts, a Critic hunts for gaps and weaknesses, the Writer revises, the Critic re-reviews, and quality converges through iteration.
Coopetition is the most nuanced pattern. In a policy-making system, pro and con agents each push their positions hard, but both ultimately serve the shared goal of "arrive at a better policy." The critical primitive here is negotiation—the ability to concede, trade, and synthesize without losing the adversarial edge that makes the structure valuable in the first place.
These three aren't discrete categories. They're a spectrum, and a well-designed system slides along it as a task progresses.
Static vs. Dynamic Orchestration: The Price of Flexibility
One of the most consequential decisions in orchestration is static versus dynamic.
In a static setup, everything is pinned down in advance. "Agent A is always the Critic; Agent B is always the Writer." Roles and identities are fixed. The upside is predictability and simplicity; the downside is rigidity.
Dynamic orchestration comes in two flavors.
The first is dynamic role allocation: roles are predefined, but who fills each role is decided at runtime. Say you have three candidates for the Critic role—a lightweight Critic, a strict Critic, and a security-specialized Critic. When the draft quality is low, you call the strict one; right before final submission, you swap in the security specialist.
The second, and more powerful, is dynamic agent spawning: you instantiate a brand-new agent with a brand-new role on the fly. If step 3 of a workflow suddenly calls for a market-research function that wasn't in the original plan, the orchestrator spins up a new agent instance with a surveying persona, runs it, and tears it down when the work is done to reclaim resources.
This dynamic pattern is where production systems really start to shine. In our proposal-writing MAS, when a deadline is tight and the workload is heavy, the Proposal Manager can request additional capacity from an HR Coordinator agent. The HR Coordinator consults a capability database, synthesizes the optimal persona for the job, attaches the right tools, grants scoped database permissions, and spawns a new Writer agent on the spot. AutoGen's GroupChatManager is a well-known implementation of this kind of dynamic turn-taking and routing [8].
When you're building a production-grade MAS, this static-versus-dynamic decision is what determines how flexible—and how complicated—your system will end up.
Communication Protocols: How Information Flows
The efficiency of inter-agent communication translates directly into system performance. Two contrasting approaches are worth walking through in detail.
MetaGPT — The Vertical Architecture
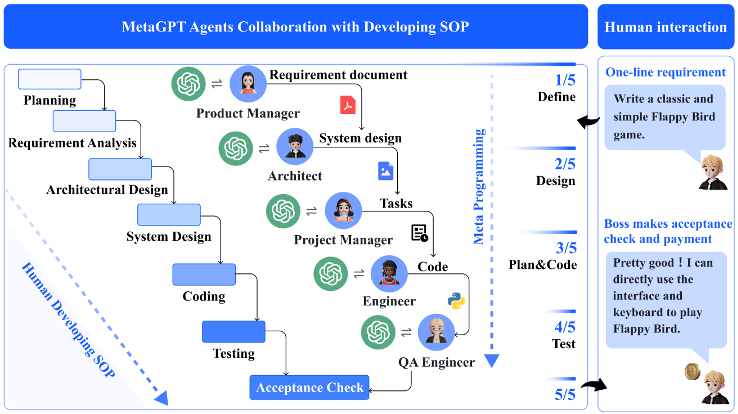
Product Manager → Architect → Project Manager → Engineer → QA Engineer form a vertical pipeline, with information shared through a publish-subscribe mechanism [6].
MetaGPT [6] is the canonical vertical architecture. Its two key contributions are, first, enforcing structured output to cut down on conversational noise between agents, and second, adopting a publish-subscribe mechanism for information sharing.
The publish-subscribe setup is more clever than it looks at first. All information lives in a single shared space, but each agent is steered to read only what's relevant to its goals and tasks. The way this works: structured messages carry meta-information (classification tags), agents carry their own role information, and a match between the two determines which messages an agent subscribes to.
You might ask: if each agent only reads its own slice, why not just route each slice directly to the right recipient in the first place? The answer is that fragmenting information generation across agents creates asymmetry in what each agent knows, opens the door to hallucinations, and often produces either too much or too little context on the receiving end. Laying a single ground truth in a shared space and letting each agent pull what it needs is strictly better for consistency.
DyLAN — The Horizontal Architecture
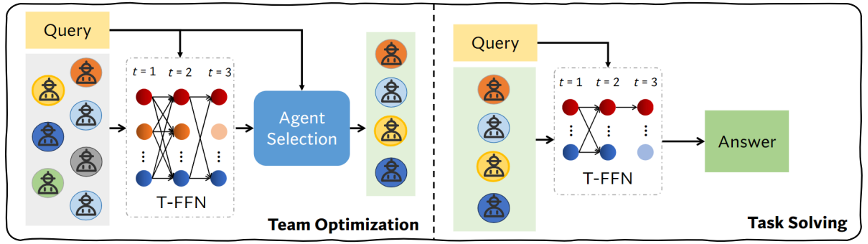
Left (Team Optimization): agents collaborate in a shared thread, and contribution-based Agent Selection happens at each round. Right (Task Solving): the optimized team executes the actual task [9].
DyLAN [9], by contrast, is closer to a horizontal architecture. Agents work together in a shared thread, and at each round—where a round is defined as each agent producing one message—contributions are evaluated and only the top-K agents advance. The evaluation is done either by a dedicated LLM Ranker or through peer rating.
Because collaboration is leaderless and team composition is reshuffled based on measured contribution, the team naturally optimizes itself over successive rounds. It's worth noting that the presence of an external LLM Ranker means DyLAN isn't purely horizontal—"substantially horizontal" is a more honest description.
The contrast between these two approaches points to something important: quality of information (MetaGPT's structured output plus publish-subscribe) and quality of participants (DyLAN's performance-based team reshuffling) are both levers worth pulling, and the most effective real-world systems tend to combine both ideas.
What This Means for Agentria
Put MetaGPT and DyLAN side by side and you realize they're attacking the same problem from opposite ends: inter-agent communication cost. MetaGPT compresses information flow so each agent only reads what it needs. DyLAN compresses the number of speakers by culling low-contribution agents every round. One narrows the channel; the other shrinks the sender pool. Both are, at the core, strategies to reduce total token consumption across the system.
For a B2B multi-agent builder like Agentria, the implication is direct. The question enterprise customers actually ask when we pitch them a multi-agent system is: "Is this worth what it costs?" Once you factor in the messages agents send each other, API costs scale faster than agent count. No matter how elegant your topology or how sophisticated your collaboration pattern, if the token bill is unmanageable, the system never makes it to production. Communication efficiency isn't an optimization—it's a precondition.
Closing Thoughts
Across these two posts, we started from the fundamental properties of LLMs and worked our way up to a full picture of multi-agent architecture as a systematic response to their limitations. As the Collaborative Scaling Law shows, this direction rests on experimentally validated ground [10].
A multi-agent system is not "several agents running at once." The way temperature emerges from an ensemble of molecules in statistical mechanics, or the way consciousness emerges from neural networks in neuroscience, system-level capability in MAS emerges from the interplay of specialized agents—how they're connected (topology), what incentive structure they operate under (cooperation, competition, coopetition), and how they exchange information (communication protocol). And none of it becomes production-viable until you have evaluation and feedback machinery transparent enough to trust.
Which is exactly why multi-agent system design is engineering and organizational design at the same time.
References
[1] Bengio et al., "Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks," NeurIPS 2015.
[2] Huang et al., "Large Language Models Cannot Self-Correct Reasoning Yet," ICLR 2024.
[3] Anthropic, "How we built our multi-agent research system," Anthropic Engineering Blog, 2025. https://www.anthropic.com/engineering/multi-agent-research-system
[4] Tomašev, Franklin, Jacobs, Krier, and Osindero, "Distributional AGI Safety," Google DeepMind, arXiv:2512.16856, December 2025.
[5] Wang et al., "Self-Consistency Improves Chain of Thought Reasoning in Language Models," ICLR 2023.
[6] Hong et al., "MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework," ICLR 2024.
[7] Qian et al., "ChatDev: Communicative Agents for Software Development," arXiv:2307.07924, 2023.
[8] Wu et al., "AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation," ICML 2024.
[9] Liu et al., "A Dynamic LLM-Powered Agent Network for Task-Oriented Agent Collaboration," COLM 2024.
[10] Qian et al., "Scaling Large Language Model-based Multi-Agent Collaboration," ICLR 2025.
[11] Tran, Dao, Nguyen, Pham, O'Sullivan, and Nguyen, "Multi-Agent Collaboration Mechanisms: A Survey of LLMs," arXiv:2501.06322, January 2025.


