Multi-Agent 협업 설계의 기술
싱글 LLM의 한계를 넘어서는 멀티에이전트 시스템(MAS)은 단순한 역할 분담이 아니라, 구조·협업·커뮤니케이션 설계를 통해 창발적 지능을 만들어내는 아키텍처다. 이 글은 토폴로지, 협업 전략, 동적 오케스트레이션, 커뮤니케이션 프로토콜 등 실제 프로덕션 환경에서 MAS를 설계할 때 필요한 핵심 기술과 트레이드오프를 구체적으로 다룬다.

작성자
AI Research Team | 손우정
이전 글에서 우리는 싱글 LLM의 구조적 한계가 왜 멀티에이전트 시스템(MAS)으로의 전환을 요구하는지, Collaborative Scaling Law가 이 방향의 유효성을 어떻게 실증하는지, 그리고 Test-time Compute Scaling과 Agent Scaling이 어떻게 교차하는지를 살펴봤습니다. 이번 글에서는 한 걸음 더 들어갑니다. 먼저 멀티에이전트 시스템이 왜 단순한 "에이전트 여러 개"가 아닌지를 창발적 지능의 관점에서 짚고, 그 다음 실제 설계 시 마주하는 핵심 결정들토폴로지, 협업 전략, 커뮤니케이션 프로토콜, 평가 체계을 구체적으로 다루겠습니다.
Single Agent System의 한계 (Recap.)
멀티에이전트 설계의 이유를 다시 한번 정리하고 넘어가겠습니다. 싱글 에이전트의 한계는 네 가지 축으로 요약할 수 있습니다.
- 병렬성(Parallelism)의 부재. 단일 에이전트는 기본적으로 하나의 task가 끝나야 다른 task를 진행할 수 있습니다. 복잡한 업무에서 리서치와 코딩과 리뷰를 동시에 진행해야 하는 상황이라면, 순차 처리 방식은 심각한 병목이 됩니다.
- 상태(state)와 기억(memory)의 혼재. Single Agent는 같은 대화/작업 컨텍스트 안에서 역할을 바꾸므로, 메모리와 맥락이 섞이기 쉽습니다. 한 번 잘못 생성된 토큰이나 가정이 들어가면, 이후의 모든 생성은 해당 오류를 조건으로 진행됩니다[1]. 이것은 LLM의 자기회귀적 특성에서 비롯되는 본질적 문제입니다.
- 독립적 검증 / 상호견제의 한계. 단일 에이전트의 내부 Critic/Verification은 근본적으로 같은 모델의 자기검열입니다. 같은 모델이 같은 컨텍스트를 보고 자기 답을 다시 검토하는 구조에서는, 독립적 견제가 아니라 자기합리화가 발생합니다. Huang et al.의 ICLR 2024 연구가 밝혔듯, intrinsic self-correction의 효용에는 명확한 한계가 있습니다[2].
- 보안 / 단일 장애점(Single Point of Failure). 단일 에이전트가 실패하거나 해킹당했을 때 전체 시스템이 동작 불가 상태가 됩니다. 멀티에이전트 시스템에서는 하나의 에이전트가 실패해도 다른 에이전트가 대체하거나 시스템이 graceful degradation할 수 있습니다.
이 네 가지 한계를 극복하기 위해, 이제 에이전트들이 어떻게 협업할 것인가를 설계해야 합니다. 그런데 그 전에, 멀티에이전트 시스템이 왜 단순히 "에이전트를 여러 개 만드는 것" 이상인지에 대한 관점 하나를 먼저 공유하겠습니다.
멀티에이전트의 창발적 지능
멀티에이전트 시스템은 단순히 에이전트를 여러 개 띄우는 것을 넘어섭니다. 모델이 일정 수준의 지능에 도달하고 나면, 시스템 성능을 한 단계 더 끌어올리는 가장 효과적인 방법 중 하나는 여러 에이전트를 어떻게 협력시키느냐로 옮겨갑니다. 개별 에이전트의 능력을 단순히 합산하는 것이 아니라, 에이전트들이 어떤 구조로 연결되고 상호작용하느냐에 따라 시스템 수준에서 개별 에이전트로는 도달할 수 없었던 새로운 능력이 창발(emerge)합니다.
지난 10만 년 동안 개별 인간이 극적으로 더 똑똑해진 것은 아니지만, 인류 사회는 집단 지성과 조정 능력 덕분에 정보화 시대에 기하급수적으로 더 강력해졌습니다[3]. 분업과 시장과 제도와 커뮤니케이션 인프라를 통해 수많은 개인의 능력이 결합되면서 문명 수준의 산출물이 만들어졌습니다. 같은 논리가 AI 에이전트에도 적용될 수 있습니다. 일반 지능을 갖춘 에이전트라 하더라도 단독으로 작동할 때는 한계에 부딪히던 것이, 적절히 조율된 에이전트 그룹을 갖추게 되면 개별 에이전트의 단순 합산을 훨씬 뛰어넘는 결과를 낼 수 있습니다.
이 관점에서 진정으로 강력한 AI 시스템이 갖추어야 할 핵심 역량은 네 가지로 정리할 수 있습니다.
- 적응성(Adaptivity)—변화하는 환경에 동적으로 대응하는 것.
- 맥락 인식(Context-Awareness)—영속적 상태와 메모리를 유지하는 것.
- 갈등 해결(Conflict Resolution)—상충하는 요구 사이에서 조율하는 것.
- 장기 계획(Long-term Planning)—여러 행동을 조율하고 장기적 의사결정을 내리는 것.
단일 모델 하나에게 이 네 가지를 동시에 최고 수준으로 요구하는 것은 비효율적이지만, 멀티에이전트 시스템에서는 각 역량을 전문화된 에이전트들의 협업으로 분산 구현할 수 있습니다. 학계에서는 최근 이러한 관점을 패치워크 AGI 가설(patchwork AGI hypothesis)이라는 이름으로 정식화하기도 했습니다. 보완적 능력을 가진 sub-AGI 에이전트들의 조율을 통해 일반 지능 수준의 능력이 먼저 발현될 수 있다는 주장입니다[4].
그렇다면, 이 협업을 구체적으로 어떻게 설계해야 할까요?
협업 전략의 세 가지 패러다임
에이전트들이 협력하는 방식은 크게 세 가지 패러다임으로 구분할 수 있습니다. Rule-based 협업은 가장 단순한 형태입니다. 여러 에이전트가 같은 문제에 대해 각자 답을 내고, Majority Voting으로 최종 결과를 결정합니다. Self-Consistency[5]가 대표적입니다. 구현이 간단하고 결과가 예측 가능하지만, 에이전트 간에 실질적인 정보 교환이 일어나지 않기 때문에 복잡한 태스크에서는 한계가 뚜렷합니다.
Role-based 협업은 실제 조직 구조를 모방한 방식입니다. Product Manager, Solution Architect, Developer, QA가 각자의 전문 역할을 수행하며, MetaGPT[6]나 ChatDev[7] 같은 프레임워크가 이 방식을 채택하고 있습니다. "제품 출시 보고서 작성 + 리스크 평가"라는 요청이 들어오면, Orchestrator가 이를 분해해서 리서치 단계는 Research role에게, 분석은 Analysis role에게 배분합니다. 조직에서 업무를 분장하는 것과 본질적으로 같은 원리입니다.
Model-based 협업은 가장 고급 패러다임입니다. 에이전트가 상대방의 의도나 상태를 확률적으로 추론하는 Theory of Mind(ToM) 기반 접근입니다. 게임 환경에서 상대의 전략을 예측하고 적응하는 방식이 대표적이며, 불확실성이 큰 환경에서 강력하지만 구현 복잡도가 상당히 높습니다.
여기서 핵심 통찰은, 하나의 태스크 안에서도 이 전략들이 혼합되고 동적으로 전환될 수 있다는 것입니다. 초기에는 에이전트들이 협력(Cooperation)하다가, Critic 에이전트가 등장하면서 경쟁(Competition) 형태로 전환되고, 궁극적으로는 더 좋은 결과라는 공동 목표를 위해 다시 수렴하는 Coopetition 패턴이 실제 프로덕션 시스템에서 가장 효과적인 경우가 많습니다.
Collaboration Topology: 구조가 성능을 결정합니다
협업 전략을 정했다면, 다음 결정은 에이전트들을 어떤 구조로 연결할 것인가입니다.
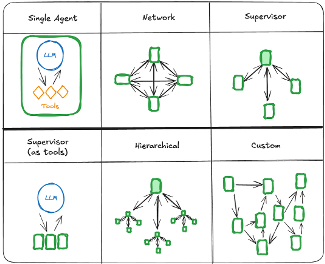
Single Agent, Network, Supervisor, Supervisor(as tools), Hierarchical, Custom 등 다양한 토폴로지 구조를 한눈에 비교합니다.(source: langchain-ai)
Network(Peer-to-Peer) 구조에서는 모든 에이전트가 서로 직접 통신할 수 있습니다. 극도로 유연하지만, 에이전트 수가 늘어나면 통신 복잡도가 O(n²)으로 증가합니다. 브레인스토밍이나 토론처럼 다양한 관점이 자유롭게 교차해야 하는 상황에 적합합니다.
Supervisor 구조는 중앙에 관리자 에이전트가 있고, 이 에이전트가 하위 에이전트들에게 태스크를 분배하고 결과를 수집합니다. 제어 흐름이 명확해서 디버깅이 용이하지만, Supervisor가 병목(bottleneck)이 될 수 있습니다. LangGraph에서 자주 쓰이는 "Supervisor as tools" 패턴은 Supervisor가 하위 에이전트들을 마치 Tool처럼 호출하는 변형인데, 에이전트를 함수처럼 재사용할 수 있다는 장점이 있습니다.
Hierarchical 구조는 Supervisor 아래에 또 다른 Supervisor가 있는 다층 구조입니다. 실제 기업 조직도와 비슷하며, 대규모 복잡한 시스템에 적합합니다.
실무에서는 이 구조들이 순수한 형태로 쓰이는 경우가 드뭅니다. 우리가 내부에서 설계한 제안서 작성 MAS를 예로 들면, Proposal Manager가 전체를 관할하는 Supervised 구조이면서, Solution Architect와 Pricing Agent 사이에는 기술 설계와 견적이 서로 영향을 주고받아야 하므로 Network(Swarm) 구조가 형성됩니다. 하나의 시스템 안에서 Supervised와 Swarm이 공존하는 하이브리드 토폴로지입니다.
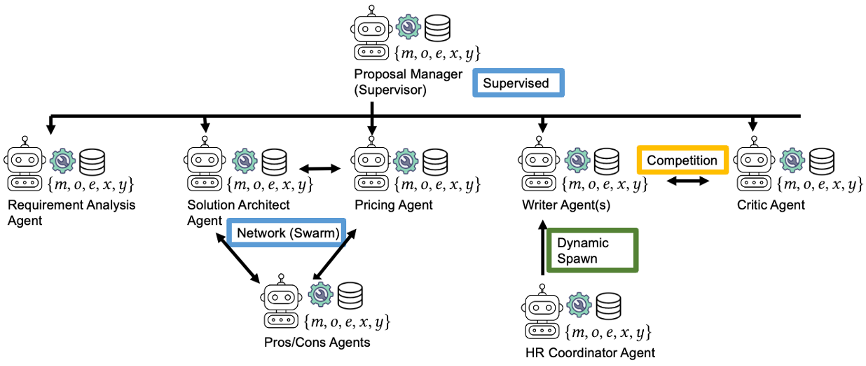
Proposal Manager(Supervisor)가 전체를 관할하면서, Solution Architect ↔ Pricing Agent 사이에는 Network(Swarm) 구조, Writer Agent ↔ Critic Agent 사이에는 Competition 구조, HR Coordinator를 통한 Dynamic Spawn이 공존합니다.
중요한 건, 어떤 토폴로지가 무조건 좋다는 것이 아니라, 태스크의 특성에 따라 적절한 구조를 선택해야 한다는 점입니다.
Cooperation, Competition, Coopetition: 인센티브 구조의 설계
토폴로지가 구조라면, 에이전트 간 상호작용의 성격은 인센티브 구조에 해당합니다.
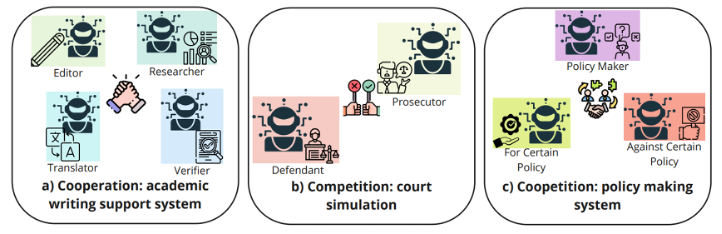
Cooperation(협력) 에서는 모든 에이전트가 공동 목표를 향해 분업합니다. 학술 논문 작성 시스템에서 Editor가 문서를 편집하고, Researcher가 자료를 조사하고, Translator가 번역하고, Verifier가 품질을 검증하는 구조가 대표적입니다.
Competition(경쟁) 에서는 에이전트들이 서로 대립하는 목표를 가집니다. 법정 시뮬레이션에서 Prosecutor가 유죄를 입증하려 하고, Defendant가 무죄를 주장하는 구조입니다. 이런 Adversarial Debate 구조는 논증의 질을 높이는 데 효과적이고, LLM의 hallucination을 잡는 데도 활용됩니다. Writer가 초안을 작성하면 Critic이 누락과 약점을 지적하고, Writer가 수정하고, 다시 Critic이 검토하는 반복을 통해 품질이 수렴하는 패턴이 대표적입니다.
Coopetition(협력+경쟁) 은 가장 정교한 형태입니다. 정책 결정 시스템에서 찬성 측과 반대 측 에이전트가 각자의 주장을 펼치면서, 궁극적으로는 "더 좋은 정책 결정"이라는 공동 목표를 위해 협력합니다. 여기서 핵심은 Negotiation입니다.
이 세 가지는 이산적 범주가 아니라 하나의 스펙트럼이며, 동일 시스템 내에서도 태스크 진행에 따라 동적으로 전환됩니다.
Static vs Dynamic Orchestration: 유연성의 대가
오케스트레이션에서 가장 중요한 설계 결정 중 하나가 Static vs Dynamic 선택입니다.
Static 방식에서는 모든 것이 미리 정의되어 있습니다. "Agent A는 항상 Critic이고, Agent B는 항상 Writer다." 역할과 에이전트의 정체성이 고정되어 있습니다. 예측 가능하고 구현이 단순하지만, 유연성이 떨어집니다.
Dynamic 방식은 두 가지 형태로 나뉩니다.
첫째, Dynamic Role Allocation은 역할 자체는 미리 정의되어 있지만, 누가 그 역할을 수행할지가 런타임에 결정됩니다. 예를 들어 Critic 역할을 수행할 후보가 세 개 있다고 합시다—가벼운 Critic, 엄격한 Critic, 보안 특화 Critic. 초안 품질이 낮으면 엄격한 Critic을, 최종 제출 직전에는 보안 특화 Critic을 호출하는 식입니다.
둘째, Dynamic Agent Spawning은 아예 새로운 역할의 에이전트를 즉석에서 생성하는 것입니다. Step 3에서 갑자기 시장조사 역할이 필요해졌다면, Orchestrator가 Surveying persona를 가진 에이전트 인스턴스를 새로 만들어서 투입합니다. 작업이 끝나면 해당 인스턴스를 제거해서 리소스를 절약할 수도 있습니다.
이 Dynamic 방식이 프로덕션에서 특히 강력한 사례가 우리가 설계한 제안서 작성 시스템에 있습니다. 마감이 촉박한데 작업량이 많을 때, Proposal Manager가 HR Coordinator Agent에게 추가 리소스를 요청합니다. HR Coordinator는 역량 데이터베이스를 바탕으로 최적의 persona를 생성하고, 어떤 tool을 붙여줄지, 어떤 DB에 대한 접근 권한을 줄지를 결정한 뒤 새로운 Writer Agent를 spawn해서 투입합니다. AutoGen의 GroupChatManager가 이런 동적 턴 할당과 라우팅을 담당하는 대표적인 구현체입니다[8].
실제 프로덕션 레벨의 Multi-Agent System을 만들 때, 이 Static vs Dynamic 결정이 시스템의 유연성과 복잡도를 크게 좌우합니다.
커뮤니케이션 프로토콜: 정보가 흐르는 방식
에이전트 간 커뮤니케이션의 효율성은 전체 시스템 성능에 직접적으로 영향을 미칩니다. 여기서 두 가지 대조적인 접근을 비교해보겠습니다.
MetaGPT — Vertical Architecture의 대표
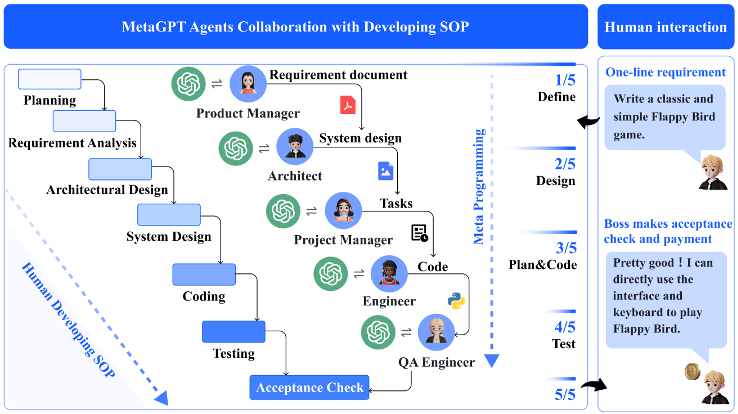
Product Manager → Architect → Project Manager → Engineer → QA Engineer가 수직적 분업을 따르며, publish-subscribe 메커니즘으로 정보를 공유합니다[6].
MetaGPT[6]는 Vertical Architecture의 대표적 사례입니다. 이 시스템의 핵심 기여는 두 가지인데, 하나는 에이전트 간의 무의미한 잡담(Conversational Noise)을 방지하기 위해 structured output을 강제하는 것이고, 다른 하나는 정보 공유에 publish-subscribe 메커니즘을 도입한 것입니다.
publish-subscribe 메커니즘의 작동 방식이 흥미롭습니다. 한 공간에 모든 정보를 공유하되, 각 에이전트는 자기 목표와 과업에 관련된 정보만 읽도록 유도합니다. 이를 위해 모델이 출력하는 structured message에 메타 정보(분류 태그)를 포함시키고, 에이전트 쪽에서도 자기 역할 정보를 보유하고 있어서, 두 정보를 매칭해서 관련 정보만 연결(subscription)하는 것입니다.
왜 관련 정보만 볼 거면 처음부터 따로따로 전달하면 되지 않느냐고 물을 수 있습니다. 핵심은, 정보를 에이전트별로 분리 생성하면 에이전트 간 정보 위격이 발생하거나, 할루시네이션이 끼어들거나, 과하거나 부족한 정보가 전달되는 문제가 생길 수 있다는 것입니다. 한 공간에 동일한 ground truth를 깔아두고 거기서 관련 정보를 선택적으로 픽업하는 방식이 정보 일관성 측면에서 우월합니다.
DyLAN — Horizontal Architecture의 대표
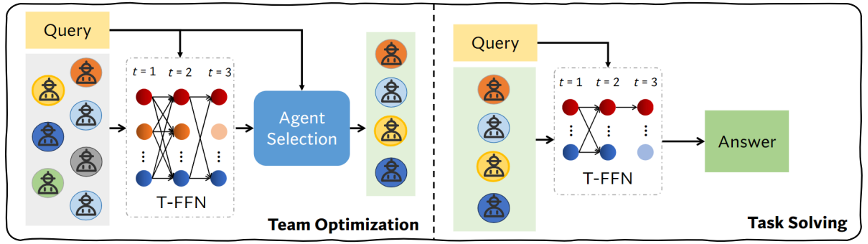
왼쪽(Team Optimization): 공용 스레드에서 에이전트들이 과업을 수행하고 라운드마다 기여도 기반 Agent Selection이 이루어집니다. 오른쪽(Task Solving): 최적화된 팀이 실제 태스크를 수행합니다[9].
반면 DyLAN[9]은 Horizontal Architecture에 가깝습니다. 이 구조에서는 공용 스레드에서 에이전트들이 함께 과업을 수행한 뒤, 라운드마다 각 에이전트의 기여도를 평가하고, 상위 Top-K 에이전트만 다음 라운드에 진출시킵니다. 여기서 라운드란, 모든 에이전트가 각 한 개의 메시지를 생성하는 것이 하나의 스텝입니다. 기여도 평가는 별도의 LLM Ranker 또는 에이전트 간 peer rating으로 이루어집니다.
리더 없이 수평적으로 협력한 뒤 성과 기반으로 팀 재편이 이루어지므로, 라운드를 반복할수록 팀 구성이 자연스럽게 최적화됩니다. 다만 별도의 LLM Ranker가 존재해서 에이전트들을 평가하는 측면이 있기 때문에, 완벽한 Horizontal Architecture까지는 아니고 "상당히 수평적인 구조를 갖고 있다" 정도로 표현하는 것이 정확합니다.
이 두 접근의 대조가 시사하는 바는 명확합니다. 정보의 질(MetaGPT의 structured output + publish-subscribe)과 참여자의 질(DyLAN의 성과 기반 팀 재편)이 모두 중요하며, 실제 시스템에서는 두 아이디어를 결합하는 것이 가장 효과적일 수 있습니다.
이것이 Agentria에 의미하는 것
MetaGPT와 DyLAN을 나란히 놓고 보면, 두 연구가 결국 같은 문제를 서로 다른 방향에서 접근하고 있다는 것을 알 수 있습니다. 바로 에이전트 간 커뮤니케이션 비용입니다. MetaGPT는 publish-subscribe 메커니즘으로 "각 에이전트가 자기에게 필요한 정보만 읽도록" 정보 흐름을 압축하고, DyLAN은 라운드마다 기여도가 낮은 에이전트를 솎아내서 "애초에 메시지를 만들어내는 참여자 수"를 압축합니다. 정보의 채널을 좁히느냐, 송신자의 수를 줄이느냐의 차이일 뿐, 둘 다 시스템 전체의 토큰 소비량을 줄이는 것이 본질입니다.
이것이 Agentria 같은 B2B 멀티에이전트 빌더에 주는 메시지는 분명합니다. 엔터프라이즈 고객에게 멀티에이전트 시스템을 서비스할 때 마주하는 질문은 "이것이 비용 대비 가치가 있는가"입니다. 에이전트 간 상호 메시지를 고려하면 에이전트 수가 늘어날수록 API 호출 비용은 그 이상으로 증가합니다. 토폴로지가 아무리 우아하고 협업 패턴이 아무리 정교해도, 토큰 청구서가 감당할 수 없는 수준이라면 프로덕션에 올라갈 수 없습니다.
마무리
이 두 편의 글을 통해 우리는 LLM의 근본적 특성에서 출발하여, 그 한계를 시스템적으로 극복하는 멀티에이전트 아키텍처의 전체 그림을 그려봤습니다. Collaborative Scaling Law가 보여주듯, 이 방향은 실험적으로 검증된 원리 위에 서 있습니다[10].
멀티에이전트 시스템은 단순히 "에이전트를 여러 개 만드는 것"이 아닙니다. 통계역학에서 온도가 분자 집단에서 창발하고, 신경과학에서 의식이 뉴런 네트워크에서 창발하듯, 전문화된 에이전트들이 어떤 구조(Topology)로 소통하고, 어떤 인센티브(Cooperation/Competition/Coopetition) 아래에서 협력하며, 어떤 커뮤니케이션 프로토콜로 정보를 교환하느냐에 따라 개별 에이전트로는 불가능했던 수준의 결과물이 나옵니다. 그리고 이 모든 것을 투명하게 평가하고 피드백할 수 있는 체계가 갖춰져야 비로소 실무에서 쓸 수 있는 시스템이 됩니다.
이것이 멀티에이전트 시스템 설계가 엔지니어링인 동시에 조직 설계인 이유입니다.
References
[1] Bengio et al., "Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks," NeurIPS 2015.
[2] Huang et al., "Large Language Models Cannot Self-Correct Reasoning Yet," ICLR 2024.
[3] Anthropic, "How we built our multi-agent research system," Anthropic Engineering Blog, 2025. https://www.anthropic.com/engineering/multi-agent-research-system
[4] Tomašev, Franklin, Jacobs, Krier, and Osindero, "Distributional AGI Safety," Google DeepMind, arXiv:2512.16856, December 2025.
[5] Wang et al., "Self-Consistency Improves Chain of Thought Reasoning in Language Models," ICLR 2023.
[6] Hong et al., "MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework," ICLR 2024.
[7] Qian et al., "ChatDev: Communicative Agents for Software Development," arXiv:2307.07924, 2023.
[8] Wu et al., "AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation," ICML 2024.
[9] Liu et al., "A Dynamic LLM-Powered Agent Network for Task-Oriented Agent Collaboration," COLM 2024.
[10] Qian et al., "Scaling Large Language Model-based Multi-Agent Collaboration," ICLR 2025.
[11] Tran, Dao, Nguyen, Pham, O'Sullivan, and Nguyen, "Multi-Agent Collaboration Mechanisms: A Survey of LLMs," arXiv:2501.06322, January 2025.


