Single LLMs Hit a Wall. Here’s What Comes Next
A single LLM quickly hits its limits on complex business problems. This article traces AI architecture evolution — from single prompts to multi-agent systems — and explores what multi-agent scaling laws mean for B2B platform design.

작성자
AI Research Team | woojung son
The pace of LLM advancement over the past few years has been nothing short of extraordinary. With the arrival of GPT-4, Claude, and Gemini, there was a prevailing sense of optimism—surely a single frontier model could handle just about anything we throw at it. But once you start tackling real-world business problems in production, it doesn't take long to realize that a single LLM call, no matter how sophisticated, simply isn't enough.
In this post, I'll trace the technical arc from the simplest form of LLM usage all the way to Multi-Agent Systems, framing the journey toward AGI as a continuous spectrum. At each stage, I'll break down the structural reasons that necessitated the jump to the next. I'll then examine what the latest research reveals about Multi-Agent Scaling Laws—and what those findings mean for platforms like Agentria that are building the infrastructure for B2B multi-agent orchestration.

Starting from a Single Prompt
This is ground zero. A user query comes in, gets wrapped with prompt engineering techniques like Chain-of-Thought, optionally augmented with external knowledge via RAG (Retrieval-Augmented Generation), and then sent to the LLM for a single-pass completion.
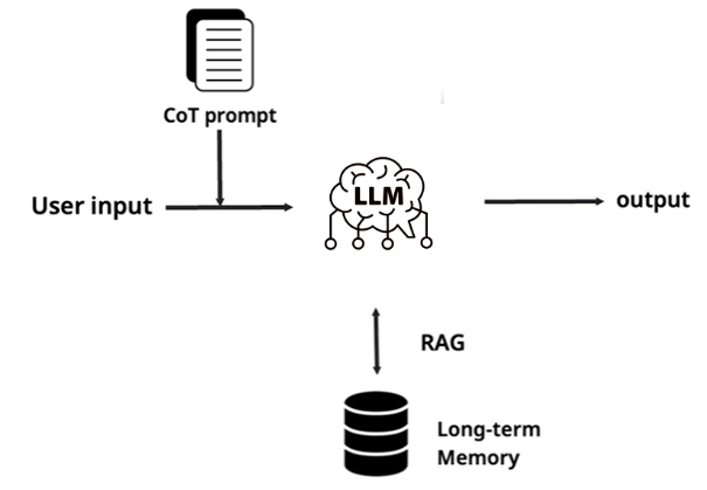
Even within this seemingly simple structure, the research landscape is remarkably rich. Wei et al.'s 2022 Chain-of-Thought paper pushed GSM8K math benchmark accuracy from 17% to 78% [1]. RAG, since Meta's Lewis et al. paper in 2020, has become a de facto standard component in production AI systems, spawning a steady stream of refinements—HyDE, query rewriting, re-ranking, and beyond [2]. On the fine-tuning front, parameter-efficient methods like LoRA and QLoRA have dramatically lowered the barrier to domain adaptation.
But the ceiling of this architecture is unmistakable. Ask most LLMs to "analyze our company's revenue data and propose next year's strategy," and you'll get back something like: "Data-driven decision-making is critical. You should segment your customers and identify market trends." Useful in the way a fortune cookie is useful. Complex problems don't yield to a single LLM call. The physical limits of the context window persist (the well-documented lost-in-the-middle phenomenon), and because LLMs are fundamentally next-token prediction machines, they lack the structural scaffolding to decompose a complex task into subtasks and recompose the results into a coherent whole.
Prompt Chaining: Enter the Pipeline
The next logical step is almost intuitive: if one call isn't enough, why not chain several together? This is Prompt Chaining—pipe the output of the first LLM call into the input of the second, insert validation gates between stages, and build a multi-step pipeline. In practice, a large number of production systems operate exactly this way, and it's particularly effective for hallucination detection and output refinement.
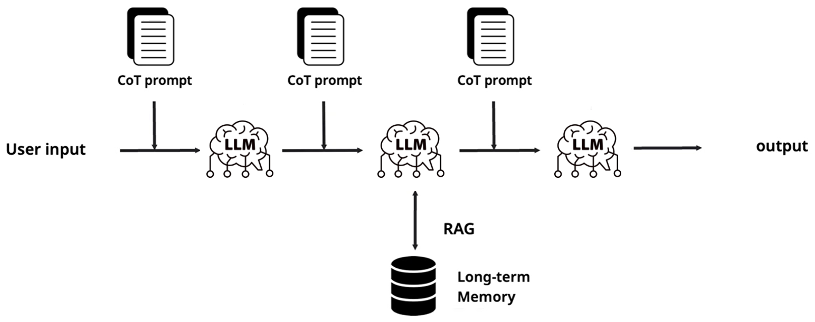
Yet this approach carries its own structural limitations. Because the pipeline follows a predetermined sequence, it struggles to adapt to unexpected situations at runtime. If one link in the chain produces a flawed output, that error propagates downstream and can corrupt the entire result. Dynamic branching—"if condition A, take path X; if condition B, take path Y"—is difficult to express cleanly. What was needed was a more flexible architecture capable of dynamic decision-making, and that's precisely what led to the concept of agents.
Single Agent: AI That Takes Action
An agent isn't just a system that answers questions—it's a system with a defined role, explicit goals, and the ability to interact with its environment. Under the ReAct (Reasoning + Acting) paradigm, an agent enters a loop: think, act, observe the result, then think again [3]. In the Plan & Execute pattern, it first constructs a plan and then executes each step sequentially. The critical distinction at this stage is that the agent possesses long-term memory, wields external tools, calls APIs, and executes code.
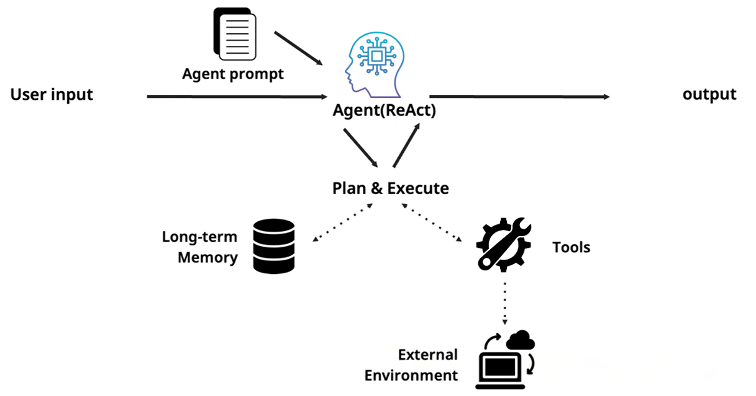
However, the single-agent paradigm hits a hard ceiling—one rooted in the autoregressive nature of the underlying LLM itself.
The Structural Weaknesses Inherent in Autoregressive Generation
An LLM doesn't produce a complete sentence in one shot. It factorizes the joint probability p(x₁:T) via the chain rule, computing the conditional probability p(xₜ | x<ₜ) at each step, conditioned on everything generated so far. This autoregressive structure gives rise to three fundamental problems.
First, error amplification. Once a faulty token enters the prefix, every subsequent token is conditioned on that error. The generation doesn't self-correct—it compounds. Bengio et al. flagged this exposure bias problem at NeurIPS 2015, and the core issue remains: early mistakes cascade rapidly [4].
Second, self-rationalization. Even when you attach a verification step to a single agent, if the same model reviews its own output within the same context, you don't get independent critique—you get self-justification. Huang et al.'s ICLR 2024 study demonstrated clear limits to the effectiveness of LLM intrinsic self-correction [5]. The model is, in effect, grading its own homework with the answer key it already wrote.
Third, impoverished exploration of alternatives. A single agent traces one generation trajectory. Due to the nature of decoding strategies—whether greedy search or beam search—it maintains only a narrow set of candidates. There's no structural mechanism for backtracking to an earlier decision point, spawning a parallel hypothesis, and comparing the two [4].
These three limitations create a natural demand for an architecture that supports role separation, independent verification, and parallel exploration. That architecture is the multi-agent system.
Multi-Agent Systems: A Team of Specialized Experts
A multi-agent system is a collection of specialized agents collaborating to solve a problem. At the top sits a main agent—the Orchestrator—which uses a Plan & Execute strategy to delegate tasks to subordinate agents. Each subordinate agent operates with its own prompt, its own long-term memory, and its own tool set. This division of labor lets each agent focus sharply on its role, keeps individual prompts lean and targeted, and elevates overall expertise.
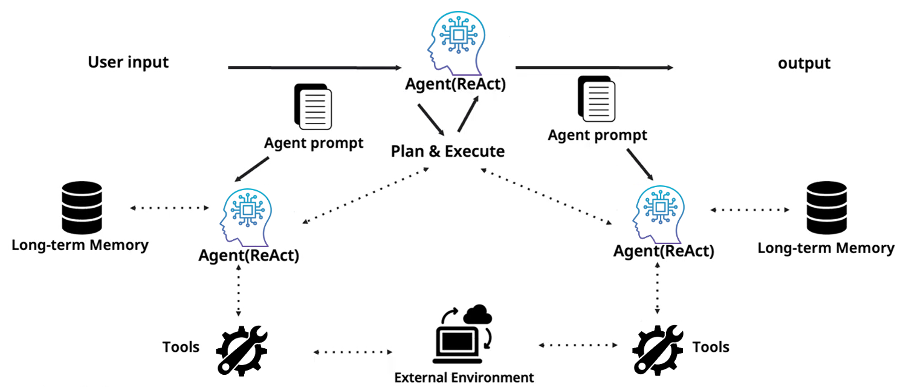
Multi-agent systems come with their own set of challenges, of course. Communication overhead between agents, the complexity of orchestration logic, debugging difficulty across distributed execution paths, and increased API call costs are all real concerns. But despite these tradeoffs, the latest research provides compelling evidence that scaling agent count translates into genuine performance gains.
Collaborative Scaling Law: Does Adding More Agents Actually Help?
For years, the primary lever for improving AI performance was making models bigger. More parameters, more data, more training compute—this was the essence of the Scaling Law discovered by Kaplan et al. in 2020 [6]. Performance improves predictably as a power law function of model size, dataset size, and training FLOPs.
Figure 6. Neural Scaling Law. Model performance (error) improves as a power law with respect to the number of model parameters (N), dataset size (D), and training compute (C) [6].
This raises a natural question: instead of scaling the model itself, could you achieve similar gains by scaling the number and collaborative structure of agents?
Qian et al.'s 2025 ICLR paper provides the first systematic answer [7]. The research team built MacNet, a multi-agent collaboration network based on DAG (Directed Acyclic Graph) topologies, and scaled the number of agents exponentially—from 2⁰ (= 1) up to 2⁶ (= 64, with mesh networks exceeding 1,000 agents).
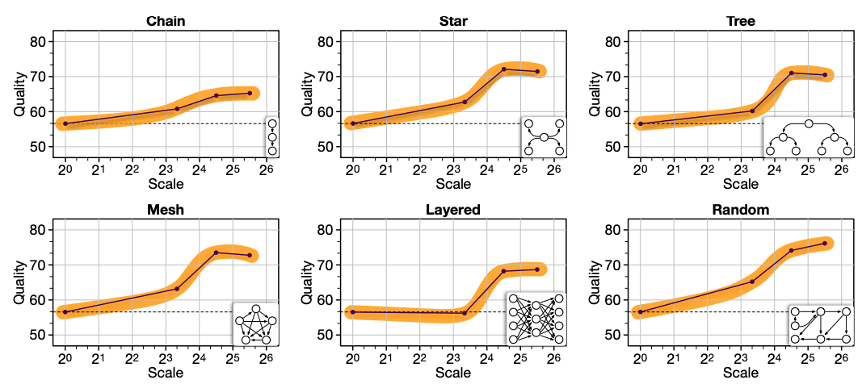
The results were striking. System performance followed a logistic growth pattern as agent count increased—slow initial growth, a steep acceleration phase, and eventual saturation in a characteristic S-curve. What's particularly notable is that this collaborative emergence occurred earlier than traditional neural emergence. The authors attribute this to the fact that agent scaling promotes multidimensional consideration through interactive reflection and refinement processes [7].
Another key finding concerns the impact of topology. Irregular topologies consistently outperformed regular ones. A naïve Full Connection approach maximizes the raw number of interactions, but the resulting information redundancy and noise can actually degrade performance or reduce efficiency. The takeaway: it's not about maximizing interaction count, but about designing structures where agents engage in deep, meaningful exchanges with the right neighbors [7].
Test-Time Compute Scaling: The Other Axis
In 2024, researchers discovered a fundamentally different scaling axis. Instead of making the model larger, you let an already-trained model think longer at inference time—and performance goes up. OpenAI's o1 model exemplifies this approach. Rather than generating an immediate response, o1 produces an extended internal chain-of-thought, explores multiple reasoning paths, reviews its own answers, and then delivers a final response. The more "thinking time" you allocate, the better it performs on reasoning-heavy benchmarks like AIME [8].
This is known as Test-time Compute Scaling—the counterpart to Pre-training Scaling. A useful analogy: to ace an exam, you can either (1) study longer beforehand, or (2) get more time during the exam itself. Remarkably, under certain conditions, giving a smaller model more "exam time" can outperform a single call to a much larger model [8].
Multi-agent systems represent the most sophisticated form of Test-time Compute Scaling. Best-of-N sampling—generating multiple responses from the same model and picking the best—is one form of test-time compute. But multi-agent systems go further. Each agent brings a different specialization, examines the problem from a different angle, and verifies independently. The inference compute generated in this process isn't mere repetition—it's structured collaboration. The Collaborative Scaling Law [7] provides empirical proof that this structured approach to inference-time reasoning is far more effective than naive repetition.
What This Means for Platform Design
Translating these findings into the context of a B2B multi-agent platform like Agentria yields several concrete design principles.
Topology matters more than agent count. When customers design their agent systems, the connection structure between agents is more consequential than sheer numbers. The platform should provide topology optimization tools or recommend proven structures based on task type—sparse irregular graphs over dense full connections, for instance.
Respect the saturation point. The logistic growth pattern in Collaborative Scaling means that beyond a certain threshold, adding more agents yields diminishing returns. The platform needs mechanisms to detect this saturation point and surface it to users as actionable feedback—preventing wasted compute and cost.
Closing Thoughts
The progression from single prompts to multi-agent systems isn't just a story of incremental technological improvement. It's a deliberate, architecture-level effort to overcome the structural limitations that emerge from LLMs being, at their core, probabilistic sequence models.
To summarize, there are three axes for scaling AI performance: making models bigger (Model Scaling), letting models think longer at inference time (Test-time Compute Scaling), and increasing the number and collaborative structure of agents (Agent Scaling). The Collaborative Scaling Law presented at ICLR 2025 [7] establishes that the third axis is not just an intuition—it's an empirically validated principle. And multi-agent systems sit precisely at the intersection of the second and third axes: they invest inference-time compute in the form of structured collaboration.
In the next post, we'll dive into the practical mechanics of multi-agent system design—cooperation, competition, and coopetition strategies, topology patterns, communication protocols, and evaluation methodologies for MAS.
References
[1] Wei et al., "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models," NeurIPS 2022.
[2] Lewis et al., "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks," NeurIPS 2020.
[3] Yao et al., "ReAct: Synergizing Reasoning and Acting in Language Models," ICLR 2023.
[4] Bengio et al., "Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks," NeurIPS 2015.
[5] Huang et al., "Large Language Models Cannot Self-Correct Reasoning Yet," ICLR 2024.
[6] Kaplan et al., "Scaling Laws for Neural Language Models," OpenAI, 2020.
[7] Qian et al., "Scaling Large Language Model-based Multi-Agent Collaboration," ICLR 2025.
[8] Snell et al., "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters," ICLR 2025.

