Real-Time Labeling Interfaces: Turning Clinical Judgment into AI Training Data
A psychiatrist rating "It's tough, but manageable" as 3/3 relies on reasoning that post-hoc labeling often loses. A joint study by Genesis Lab, UNIST, and Seoul National University Hospital, presented at IASDR 2025, shows how interface design can capture that reasoning as training data.

There is a moment in psychiatric counseling when a clinician hears a single sentence and forms a judgment. That judgment rarely comes from the sentence alone. It emerges from the patient's tone, pauses, earlier answers, and the rhythm set in the opening minutes of the session. Most mental health AI systems have struggled to learn this flow. They are trained on labels applied after the session ends, on transcripts where the original context has already been lost.
Genesis Lab, working with the Department of Design at UNIST and the Department of Psychiatry at Seoul National University Hospital, designed an interface that restructures this process. It lets clinicians attach labels at the very moment a judgment is formed. The work was presented at IASDR 2025 (International Association of Societies of Design Research), held in Taiwan in December 2025.
Paper: Exploring Design Contributions to Mental Health AI: Structuring Clinical Judgment Through Real-Time Data Labeling Interfaces
Authors: Jieun Lee, Hwang Kim, Chajoong Kim (UNIST Department of Design), Bong-Jin Hahm (Seoul National University Hospital, Department of Psychiatry), Daehun Yoo (Genesis Lab)
Venue: IASDR 2025, Taipei, Taiwan, December 2–5, 2025
Link: doi.org/10.21606/iasdr.2025.964
What happens when AI only learns the outcomes of judgment
Traditional machine learning pipelines record expert judgment after the fact. Clinicians watch recordings or read transcripts and attach labels such as "anxiety: 3 out of 3." The approach is easy to implement, but it has a structural flaw. The context in which the judgment was formed is already gone.
Clinical judgment does not arrive in a single moment. It builds up through revisiting earlier answers, checking tone, and asking follow-up questions [1]. Post-hoc labeling flattens this cumulative process into discrete events. Datasets end up holding only the outcome, not the reasoning behind it.
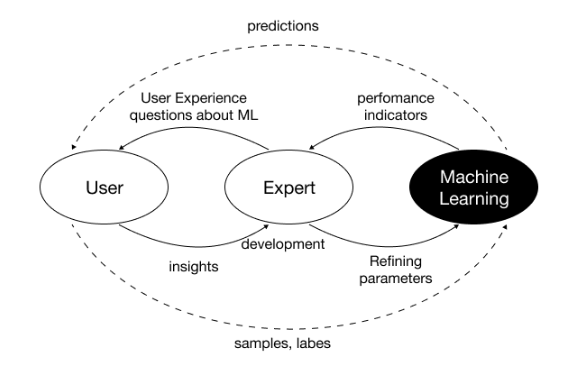
Models trained on such data carry two problems. First, when different annotators assign different scores to the same utterance, the model absorbs the inconsistency. Second, explaining a model's output becomes difficult because the reasoning was never captured on the input side.
This paper shifts the problem upstream. Instead of asking "how do we explain the model," it asks "what structure should the training data have in the first place."
Implementing Interactive Machine Teaching as an interface
The framework behind the design is Interactive Machine Teaching (IMT). IMT positions experts not as data suppliers but as designers of the learning context [2]. Ramos and colleagues describe three core principles:
- Experts must be able to visualize and articulate their decision-making process
- Feedback must convey the structure of judgment, not merely whether an answer is correct
- Experts must participate as co-creators throughout data collection and model training
The research team built the interface through a participatory design process with licensed psychiatrists. The label vocabulary, feedback timing, and degree of flexibility in the session flow were all shaped by clinician input.
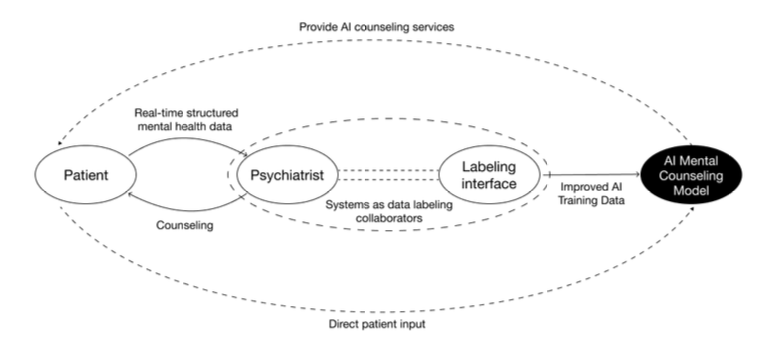
Three design axes
Anchoring points. The clinical meaning of each score is surfaced repeatedly as the score is being entered. Criteria such as "1 point carries little clinical significance, while 3 points indicates a signal that must never be overlooked" stay visible on the screen. The mechanism works like a shared ruler: it keeps multiple annotators aligned on the same units.
Real-time synchronization. Microphone input is automatically timestamped against each label. Which utterance received which score, in what order, is preserved intact.
Support for non-linear conversation. Psychiatric counseling rarely follows a fixed script. Clinicians skip questions, return to earlier topics, or reorder prompts. The interface accommodates this flexibility while keeping the labeling structure consistent.
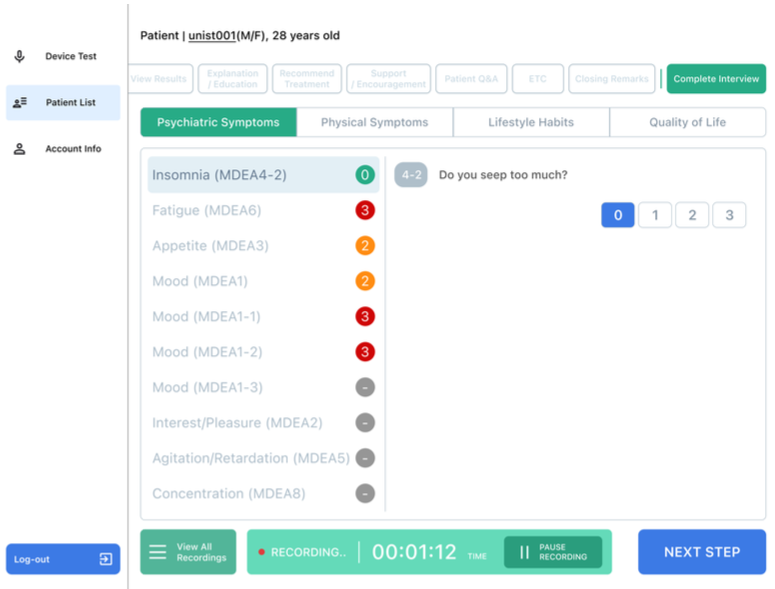
Study design
Two board-certified psychiatrists conducted five actual mental health counseling sessions across two university hospitals. P1 was a seasoned user with 80 prior interface sessions; P2 was an early user with 10. The team combined semi-structured interviews, behavioral observation coding, and a User Experience Questionnaire (UEQ) survey. The behavioral coding framework tracked five categories: judgment delay, feature exploration failure, misinterpretation of feedback, error recovery, and operational hesitation.
Findings: what happens when the interface begins to structure judgment
From "labeling tool" to "judgment collaborator"
As sessions accumulated, clinicians' perception of the interface shifted. What started as a data entry screen became a tool for preventing omissions, and then moved further into something that structured judgment itself.
"It's less a decision-making tool and more of a recorder that helps me avoid missing anything." — P1
"Repeated use helped me refine how I phrase questions, and I feel less psychological distance from the technology." — P2
The shift appears in the behavioral data as well. Judgment delay events decreased across sessions, and UEQ items such as "I could use the function without thinking about it" rose steadily with repetition. By the third session, P2 gave the maximum score of 7 for simplicity, clarity, and efficiency.
Consistency follows from shared criteria
Labeling consistency does not come from technology. It comes from criteria. Before entering scores, clinicians repeatedly sought clarity on what each score meant.
"At first, I think I gave different scores for the same situation. But as the sessions continued, the criteria became more organized." — P2
When judgment criteria have not settled, the labels created produce two costs. The dataset becomes less reusable, and the reliability and generalizability of the resulting AI suffer. Repeated exposure to anchoring points works as a structural mechanism to reduce both.
Clinicians begin designing "question structures for AI learning"
As use accumulated, the clinician's role shifted more fundamentally. They moved from users of the interface to designers who restructured their questions to make AI learning possible.
"You can't just talk as you would in a normal consultation. If you want to train AI, you have to keep asking and help the patient verbalize their experience." — P2
This is where IMT's theoretical claim is demonstrated empirically. Experts are not data suppliers; they are co-designers of the learning context.

Limits: when structure presses on the relationship
The authors are explicit about two tensions the interface did not resolve.
First, the fixed question order and checklist format sometimes disrupted the natural rhythm of dialogue. The friction was most pronounced in initial consultations, where rapport must be built. The UEQ item on "accessibility of help information" remained at 4 points even through the third session.
Second, the emotional state of patients is not fully captured through language alone. Even patients experiencing moderate to severe distress often soften their expression, saying things like "It's tough, but manageable" to stay socially acceptable. A language-dependent interface risks flattening these layers of meaning.
Toward learning the reasoning, not just the decision
This approach can extend into systems like Pebble — Genesis Lab's mental health AI — as a path toward learning the reasoning behind clinical judgment. The point is not to mimic which score a clinician assigned, but to learn the grounds on which that score was reached.
What this requires is input-side design, not model-side technique. Explainable AI (XAI) has largely focused on interpreting model outputs. This paper moves the question one step upstream: if the output is to be interpretable, the input must be interpretable first, and the input is shaped by interface design.
If training data is built through real-time labeling, three things become possible:
- The sequential structure of judgment is preserved, so the model can learn why a given symptom score is 3, within its temporal context
- Anchoring points function as shared criteria, keeping data consistent even when many annotators are involved
- The clinician's process of restructuring questions becomes part of the training data itself, opening the possibility that the model learns conversational strategies that elicit meaningful responses
This direction lays a foundation for AI counseling systems that follow clinical reasoning rather than mimic surface dialogue. The study provides an academic grounding for that design methodology.
Open questions
The paper closes with three directions for future work: a multimodal interface that captures non-verbal cues, a flexible input structure that does not undermine rapport, and quantitative evaluation of how the collected data actually affects AI model performance.
Discussions of explainable AI have a long history, but most of them have focused on examining model outputs. The perspective this study offers is simple: for a model to explain its reasoning, the input must first be able to hold that reasoning.
References
[1] Benner, P.; Hughes, R. G.; Sutphen, M. Clinical reasoning, decision making, and action: Thinking critically and clinically. In Patient safety and quality: An evidence-based handbook for nurses, Vol. 2; Hughes, R. G., Ed.; Agency for Healthcare Research and Quality (US): 2008; pp. 87–102.
[2] Ramos, G.; Freitas, D. J. F.; Silva, D. S. Human–AI interaction design in interactive machine learning systems. ACM Comput. Surv. 2020, 53, Article 17.
[3] Amershi, S.; Cakmak, M.; Knox, W. B.; Kulesza, T. Power to the people: The role of humans in interactive machine learning. AI Mag. 2014, 35, 105–120.

