실시간 라벨링 인터페이스: 정신과 임상 판단을 데이터로 구조화한 방법
"힘들지만 버틸 만하다"는 환자의 말을 3점이라 판단하는 임상의의 근거는 어디에 있을까요. 기존 AI는 판단의 결과만 배웠을 뿐 근거를 놓쳤습니다. IASDR 2025에서 발표된 제네시스랩·UNIST·서울대병원 공동 연구는 라벨링 인터페이스 설계로 이 근거를 데이터로 만드는 방법을 보여줍니다.

정신과 전문의가 환자의 한 마디를 듣고 무언가를 결정하는 순간이 있습니다. 그 순간의 판단은 단일 문장에서 나오지 않습니다. 환자의 말투, 침묵, 이전 대답, 세션 초반의 어조가 겹쳐 만들어집니다. 지금까지의 정신건강 AI는 이 흐름을 충분히 학습하기 어려웠습니다. 상담이 끝난 뒤 녹취록을 놓고 전문가가 라벨을 붙이는 방식이었기 때문입니다. 그 순간의 근거는 상당 부분 손실된 상태에서 결과만 남습니다.
제네시스랩은 UNIST 디자인학과, 서울대학교병원 정신건강의학과와 함께 이 구조를 바꾸는 인터페이스를 설계했습니다. 판단이 이루어지는 그 순간에 라벨이 함께 붙는 실시간 라벨링 인터페이스입니다. 이 연구는 2025년 12월 대만에서 열린 IASDR 2025 국제 디자인 리서치 학회에서 발표됐습니다.
-논문: Exploring Design Contributions to Mental Health AI: Structuring Clinical Judgment Through Real-Time Data Labeling Interfaces
저자: Jieun Lee, Hwang Kim, Chajoong Kim (UNIST Design), Bong-Jin Hahm (서울대학교병원 정신건강의학과), Daehun Yoo (Genesis Lab)
학회: IASDR 2025, Taiwan, December 2-5, 2025
원문: doi.org/10.21606/iasdr.2025.964
AI가 판단 결과만 배우면 어떻게 되는가
전통적인 기계학습 파이프라인은 전문가의 판단을 사후에 기록합니다. 상담이 끝난 뒤 녹취나 영상을 보며 "이 발화는 불안 3점"과 같은 라벨을 붙이는 방식입니다. 이 접근은 구현이 쉽지만 구조적 한계가 있습니다. 판단이 만들어진 순간의 맥락이 사라집니다.
임상 판단은 한 번에 일어나지 않습니다. 환자의 이전 답변을 되짚고 톤을 확인하고 다시 질문하는 순환 과정에서 생성됩니다[1]. 사후 라벨링은 이 흐름을 단일 사건으로 납작하게 만듭니다. 데이터셋에는 결과만 남고 "왜 그렇게 판단했는가"는 빠집니다.
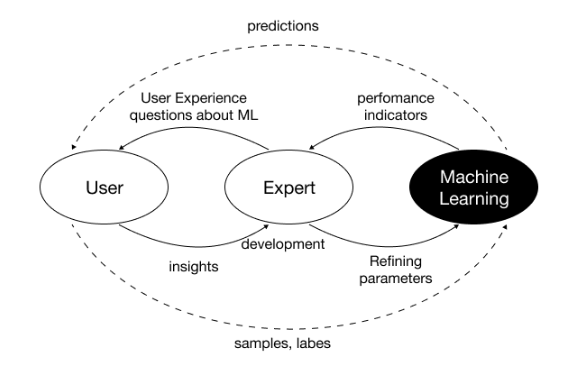
결과만 학습한 모델은 두 가지 문제를 일으킵니다. 첫째, 동일한 환자 발화에 대해 라벨러마다 다른 점수를 매길 때 모델이 편차를 그대로 학습합니다. 둘째, 모델의 출력을 해석하려 해도 입력 단계에서 이미 근거가 사라져 있기 때문에 설명이 피상적으로 흐릅니다.
이 논문은 문제를 한 단계 앞당깁니다. "모델을 어떻게 설명할 것인가"가 아니라 "학습 데이터를 어떤 구조로 모을 것인가"를 묻습니다.
Interactive Machine Teaching을 인터페이스로 구현하다
연구팀이 기반으로 삼은 프레임워크는 Interactive Machine Teaching(IMT)입니다. IMT는 전문가를 데이터 공급자가 아니라 학습 맥락의 설계자로 세웁니다[2]. Ramos가 제시한 세 가지 설계 원칙은 다음과 같습니다.
- 전문가가 자신의 판단 과정을 시각화하고 언어화할 수 있어야 한다.
- 피드백은 정답 여부가 아니라 판단 구조를 전달해야 한다.
- 전문가는 데이터 수집과 모델 학습 전 과정에 공동 창작자로 참여해야 한다.
연구팀은 정신과 전문의와 참여 설계(participatory design) 방식으로 인터페이스를 만들었습니다. 설계 과정에서 어떤 라벨 어휘를 쓸지, 어느 시점에 피드백을 줄지, 상담 흐름이 얼마나 유연해야 하는지를 임상의 의견을 반영해 조율했습니다.
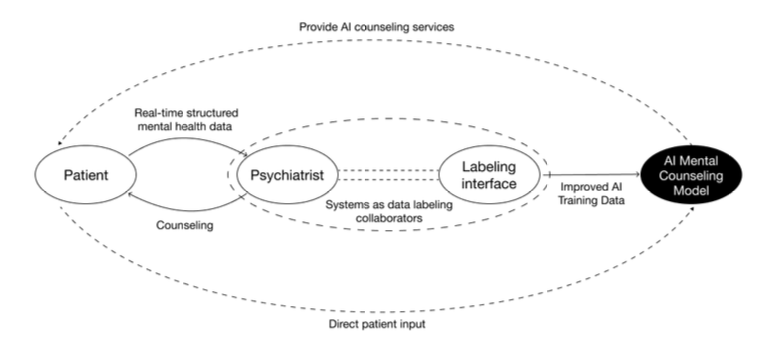
인터페이스의 세 가지 설계 축
- 앵커링 포인트(anchoring points). 점수를 매기는 순간 그 점수의 임상적 의미가 반복 제시됩니다. "1점은 임상적 의미 거의 없음, 3점은 절대 놓쳐선 안 되는 위험 신호" 같은 기준이 화면에 지속 노출됩니다. 여러 평가자가 같은 자를 쓰도록 눈금을 계속 보여주는 장치로 이해할 수 있습니다.
- 실시간 동기화. 마이크 입력이 라벨 시점과 함께 자동으로 타임스탬프됩니다. 어떤 발화에 어떤 점수가 어떤 순서로 매겨졌는지 온전히 보존됩니다.
- 비선형 대화 지원. 정신과 상담은 계획대로 흐르지 않습니다. 임상의는 질문을 건너뛰거나 주제를 다시 꺼내거나 순서를 바꿉니다. 인터페이스는 이 유연성을 허용하면서도 라벨 구조의 일관성을 유지합니다.
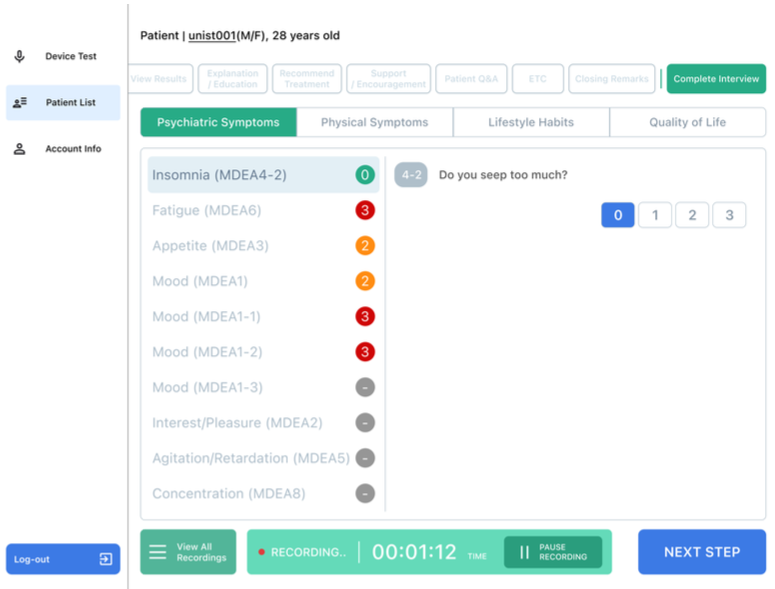
실험 설계
정신과 전문의 2명이 두 대학병원에서 다섯 건의 실제 정신건강 상담을 진행했습니다. P1은 인터페이스 사용 경험 80회의 숙련 사용자, P2는 10회의 초기 사용자입니다. 연구팀은 반구조화 인터뷰, 행동 관찰 코딩, User Experience Questionnaire(UEQ) 기반 설문을 병행했습니다. 행동 관찰 코딩에는 판단 지연, 기능 탐색 실패, 피드백 오해, 오류 복구, 조작 주저 다섯 범주가 쓰였습니다.
결과: 인터페이스가 판단을 구조화하기 시작했을 때
"라벨링 도구"가 "판단 동료"로 재정의되다
세션을 반복하며 임상의가 인터페이스를 보는 방식이 바뀌었습니다. 처음에는 단순 입력 화면이었던 것이 누락 방지 도구로 이동했고, 다시 판단을 구조화하는 협업 도구로 이동했습니다.
"결정을 내리게 하는 도구라기보다, 놓치지 않게 해주는 기록기 같습니다." — P1
"반복해서 쓰다 보니 질문하는 방식이 다듬어졌습니다. 기술과의 심리적 거리가 줄어듭니다." — P2
이 전환은 행동 데이터에서도 확인됩니다. 판단 지연 횟수가 세션이 지나며 감소했고, UEQ의 "기능을 생각하지 않고 사용할 수 있었다" 항목은 반복에 따라 꾸준히 상승했습니다. P2의 경우 3회차에 단순성, 명확성, 효율성 항목이 최고점 7점에 도달했습니다.
기준이 먼저 서야 판단이 일관된다
라벨링의 일관성은 기술이 아니라 기준에서 나옵니다. 임상의들은 점수 입력 전에 "이 점수가 무엇을 의미하는지"를 반복적으로 재확인했습니다.
"처음엔 같은 상황에도 다른 점수를 줬다고 생각합니다. 세션이 거듭되면서 기준이 정리됐습니다." — P2
판단 기준이 충분히 자리 잡지 않은 상태의 라벨은 두 가지 문제를 낳습니다. 데이터셋의 재사용 가능성이 떨어집니다. AI 모델의 신뢰성과 일반화 가능성이 훼손됩니다. 앵커링 포인트의 반복 노출은 이 문제를 줄이는 구조적 장치로 작동합니다.
임상의가 "AI 학습 고려한 질문 구조"를 설계하기 시작하다
반복 사용이 축적되자 임상의의 역할이 더 근본적으로 바뀌었습니다. 단순히 인터페이스를 쓰는 사용자가 아니라 AI 학습을 위해 질문을 재구성하는 설계자로 옮겨갔습니다.
"평소 상담처럼 말해서는 안 됩니다. AI를 학습시키려면 계속 물어보고, 환자가 자기 경험을 언어화하도록 도와야 합니다." — P2
이 지점에서 IMT의 이론적 주장이 실증됩니다. 전문가는 데이터 공급자가 아니라 학습 맥락을 구성하는 공동 설계자라는 전제입니다.

연구팀은 인터페이스가 해결하지 못한 두 가지 어려움을 명시합니다.
첫째, 고정된 질문 순서와 체크리스트 형식이 상담의 자연스러운 흐름을 끊는 경우가 있었습니다. 특히 라포(rapport)를 쌓아야 하는 초기 상담에서 이 마찰이 두드러졌습니다. UEQ "도움말 접근성" 항목은 세션을 반복해도 4점에 머물렀습니다.
둘째, 환자의 감정 상태는 언어만으로 포착되지 않습니다. 중등도 이상의 고통을 겪는 환자도 사회적 기대 때문에 "힘들지만 버틸 만하다"고 완화해서 말하는 경우가 많습니다. 고정된 언어 입력에 의존하는 인터페이스는 이런 의미의 겹을 납작하게 만들 위험이 있습니다.
판단의 근거까지 학습하는 방향으로
이 접근은 페블과 같은 시스템에서 판단의 근거까지 학습하는 방향으로 확장될 수 있습니다. 임상의가 어떤 점수를 매겼는가만이 아니라, 어떤 근거로 그 점수에 도달했는가를 함께 학습하는 경로입니다.
이를 위해 필요한 것은 모델 쪽 기법이 아니라 입력 쪽 설계입니다. 설명 가능한 AI(XAI) 분야는 그동안 "출력을 어떻게 해석할 것인가"에 집중해왔습니다. 이 논문의 주장은 한 걸음 앞으로 옮깁니다. 출력이 해석 가능하려면 입력부터 해석 가능해야 하고, 입력은 인터페이스 설계가 결정합니다.
실시간 라벨링 방식으로 학습 데이터가 구축되면 세 가지가 가능해집니다.
- 판단의 순차적 구조가 보존되어 모델이 "이 증상 점수가 왜 3점인지"를 시간적 맥락과 함께 학습할 수 있습니다
- 앵커링 포인트가 공유 기준으로 작동하여 라벨러가 여러 명이어도 데이터의 일관성이 유지됩니다
- 임상의의 질문 재구성 과정 자체가 학습 데이터의 일부가 되어 답변을 유도하는 대화 전략까지 학습할 수 있습니다
이런 방향은 임상 근거를 따라가는 AI 상담 시스템의 설계 기반이 될 수 있습니다. 이 연구가 그 설계 방법론을 학술적으로 뒷받침합니다.
앞으로의 과제
이 논문은 결론에서 세 가지 후속 과제를 명시합니다. 비언어 단서까지 포괄하는 다중모달 인터페이스, 라포를 해치지 않는 유연한 입력 구조, 수집된 데이터가 실제 AI 모델 성능에 어떤 기여를 하는지에 대한 정량적 검증입니다.
설명 가능한 AI의 논의는 오래되었지만 대부분 모델 출력을 들여다보는 데서 멈춰왔습니다. 이 연구가 제시하는 관점은 단순합니다. 모델이 이유를 설명하게 하려면 이유를 담을 수 있는 입력부터 만들어야 합니다.
References
[1] Benner, P.; Hughes, R. G.; Sutphen, M. Clinical reasoning, decision making, and action: Thinking critically and clinically. In Patient safety and quality: An evidence-based handbook for nurses, Vol. 2; Hughes, R. G., Ed.; Agency for Healthcare Research and Quality (US): 2008; pp. 87–102.
[2] Ramos, G.; Freitas, D. J. F.; Silva, D. S. Human–AI interaction design in interactive machine learning systems. ACM Comput. Surv. 2020, 53, Article 17.
[3] Amershi, S.; Cakmak, M.; Knox, W. B.; Kulesza, T. Power to the people: The role of humans in interactive machine learning. AI Mag. 2014, 35, 105–120.

