단일 LLM의 한계를 넘어서: Multi-Agent System은 왜 필요한가
단일 LLM으로 복잡한 비즈니스 문제를 해결하는 접근은 현실에서 쉽게 한계에 부딪힌다. 이 글에서는 단일 프롬프트부터 멀티 에이전트 시스템에 이르기까지 AI 아키텍처의 발전 단계를 분석하고, 각 구조가 왜 실패하거나 부족했는지 그 이유를 짚는다. 그리고 그 흐름 속에서 도출되는 멀티 에이전트 스케일링 법칙이 B2B 플랫폼 설계에 어떤 시사점을 주는지 살펴본다.

작성자
AI Research Team | 손우정
지난 몇 년간 LLM(Large Language Model)의 발전 속도는 경이로웠습니다. GPT-4, Claude, Gemini 같은 모델들이 등장하면서 "이 정도면 단일 모델 하나로 모든 걸 해결할 수 있지 않을까?"라는 기대가 팽배했습니다. 하지만 실제 프로덕션 환경에서 복잡한 비즈니스 문제를 풀어보면, 단일 LLM 호출 한 번으로는 턱없이 부족하다는 사실을 금방 깨닫게 됩니다.
이 글에서는 AGI를 향한 기술적 여정을 가장 간단한 형태의 LLM부터 Multi-Agent System까지 하나의 스펙트럼으로 조망하고, 각 단계의 아키텍처가 왜 다음 단계로 진화해야 했는지를 구조적으로 분석합니다. 그리고 최신 연구가 밝히고 있는 Multi-Agent Scaling Law의 실체를 살펴보면서, 이것이 Agentria 같은 B2B 멀티에이전트 플랫폼에 어떤 함의를 갖는지 논의하겠습니다.

싱글 프롬프트에서 시작하기
가장 기본이 되는 구조입니다. 사용자 입력이 들어오면 Chain-of-Thought 같은 프롬프트 엔지니어링 기법과 함께 LLM에 전달하고, 필요하면 RAG(Retrieval-Augmented Generation)를 통해 외부 지식을 주입한 뒤 출력을 생성합니다.
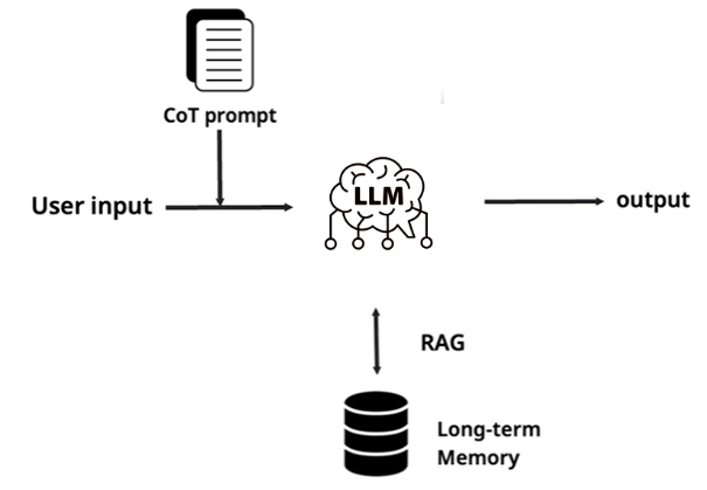
이 구조 안에서도 연구 갈래는 풍성합니다. 2022년 Wei et al.이 발표한 Chain-of-Thought 기법은 GSM8K 수학 벤치마크 정확도를 17%에서 78%로 끌어올렸습니다[1]. RAG는 2020년 Meta의 Lewis et al. 논문 이후 사실상 프로덕션 AI 시스템의 표준 컴포넌트가 되었고, HyDE, Query Rewriting, Re-ranking 같은 고도화 기법들이 계속 나오고 있습니다[2]. Fine-tuning 쪽에서도 LoRA, QLoRA 같은 Parameter-Efficient 기법 덕분에 진입 장벽이 현저히 낮아졌습니다.
하지만 이 구조의 한계는 명확합니다. "우리 회사 매출 데이터를 분석해서 내년 전략을 제안해줘"라고 요청하면, 대부분의 LLM은 "데이터 기반 의사결정이 중요합니다. 고객 세그먼트를 분석하시고, 시장 트렌드를 파악하세요" 같은 일반론적 답변을 내놓습니다. 복잡한 문제는 한 번의 LLM 호출로 해결되지 않고, context window의 물리적 한계(Lost-in-the-middle 현상)도 여전하며, LLM이 본질적으로 next token prediction 모델이기에 복잡한 태스크를 sub-task로 분해하고 다시 통합하는 구조적 사고가 근본적으로 어렵습니다.
프롬프트 체이닝: 파이프라인의 등장
"그러면 여러 단계로 쪼개면 되지 않을까?" 이 자연스러운 발상이 Prompt Chaining입니다. 첫 번째 LLM 호출의 출력을 두 번째 호출의 입력으로 연결하고, 중간에 검증 단계를 끼워넣는 식입니다. 실제로 많은 프로덕션 시스템이 이 방식으로 동작하고 있고, 할루시네이션 검증이나 출력 정제 용도로 상당히 유용합니다.
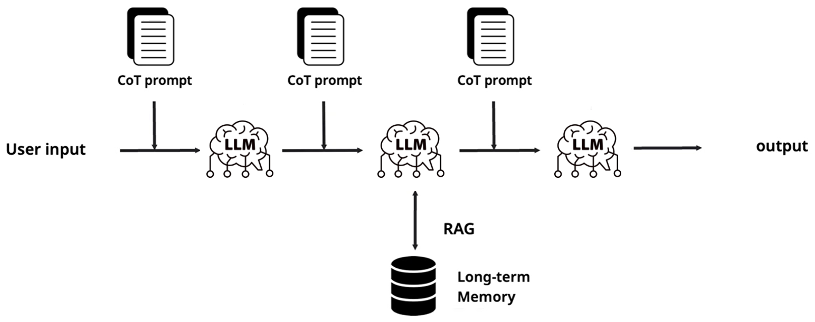
하지만 이 접근에도 구조적 한계가 있습니다. 파이프라인이 미리 정해진 순서대로만 흘러가기 때문에 예상치 못한 상황에 유연하게 대응하기 어렵습니다. 체인 중 하나가 이상한 출력을 내면 그 오류가 다음 단계로 전파되면서 결과가 엉망이 될 수 있습니다. 그리고 "이 조건이면 A 경로, 저 조건이면 B 경로"와 같은 동적 분기 처리가 제한적입니다. 그래서 더 유연하고 동적인 의사결정이 가능한 구조가 필요해졌고, 그것이 바로 Agent의 개념으로 이어집니다.
싱글 에이전트: 행동하는 AI의 등장
에이전트는 단순히 답변만 하는 것이 아니라, 역할과 목표를 가지고 환경과 실제로 상호작용하는 시스템입니다. ReAct(Reasoning + Acting) 패러다임에서는 에이전트가 생각하고, 행동하고, 결과를 관찰하고, 다시 생각하는 루프를 반복합니다[3]. Plan & Execute 패턴에서는 먼저 계획을 세우고 각 스텝을 순차적으로 실행합니다. 이 단계에서 중요한 것은 에이전트가 Long-term Memory를 갖고, 외부 Tools를 사용하고, API를 호출하고, 코드를 실행할 수 있다는 점입니다. 그러나 싱글 에이전트의 한계는 LLM의 자기회귀적(autoregressive) 특성에서 근본적으로 비롯됩니다.
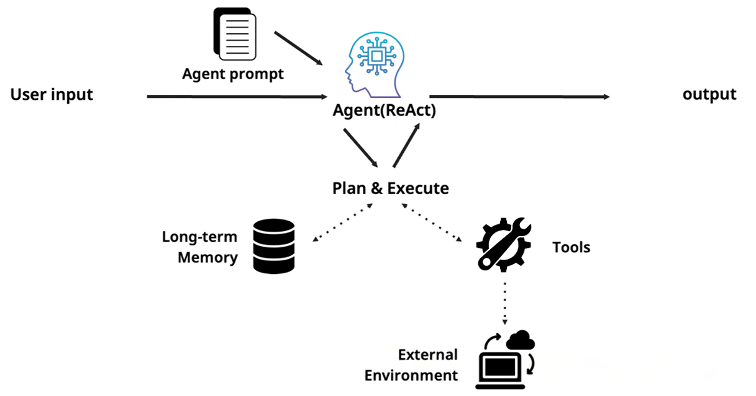
LLM의 자기회귀 특성이 만드는 구조적 약점
LLM은 문장을 한 번에 완성하는 모델이 아닙니다. 결합확률 p(x₁:T)를 체인룰로 분해해서, 매 step마다 이전까지의 prefix를 조건으로 다음 토큰의 조건부확률 p(xₜ|x<ₜ)를 반복적으로 계산하는 자기회귀 모델입니다. 이 구조는 세 가지 본질적 문제를 만듭니다.
첫째, 오류 증폭(Error Amplification)입니다. 한번 잘못 생성된 토큰이 prefix에 들어가면, 그 다음부터는 그 오류를 조건으로 계속 전개됩니다. Bengio et al.이 NeurIPS 2015에서 이미 이 문제를 지적했고, 이는 초반 실수가 빠르게 증폭될 수 있음을 의미합니다[4].
둘째, 자기합리화(Self-Rationalization) 문제입니다. 싱글 에이전트에서 검증 단계를 붙이더라도, 같은 모델이 같은 컨텍스트를 보고 자기 답을 다시 고치는 구조면 독립적 견제가 아니라 자기합리화가 되기 쉽습니다. Huang et al.이 ICLR 2024에서 발표한 연구에 따르면, LLM의 intrinsic self-correction 효용에는 명확한 한계가 있습니다[5].
셋째, 대안 탐색의 부족입니다. 단일 에이전트는 한 번의 생성 궤적을 따라가며, 그리디 서치나 빔 서치처럼 제한된 후보만 유지하는 디코딩 특성상 초반 선택을 되돌려 다른 가설을 병렬로 탐색하고 비교하기가 구조적으로 어렵습니다[4].
이 세 가지 한계가 자연스럽게 역할 분리, 독립적 검증, 병렬 탐색이 가능한 멀티에이전트 구조로의 전환을 요구합니다.
Multi-Agent System: 협업하는 전문가 집단
멀티에이전트 시스템은 여러 개의 전문화된 에이전트가 협력해서 문제를 해결하는 구조입니다. 상단에 메인 에이전트(Orchestrator)가 있고, Plan & Execute를 통해 하위 에이전트들에게 태스크를 분배합니다. 각 하위 에이전트는 자기만의 프롬프트, 자기만의 Long-term Memory, 자기만의 Tools를 갖고 있습니다. 이렇게 하면 각 에이전트가 자기 역할에 집중할 수 있고, 프롬프트도 간결해지며, 전문성도 높아집니다.
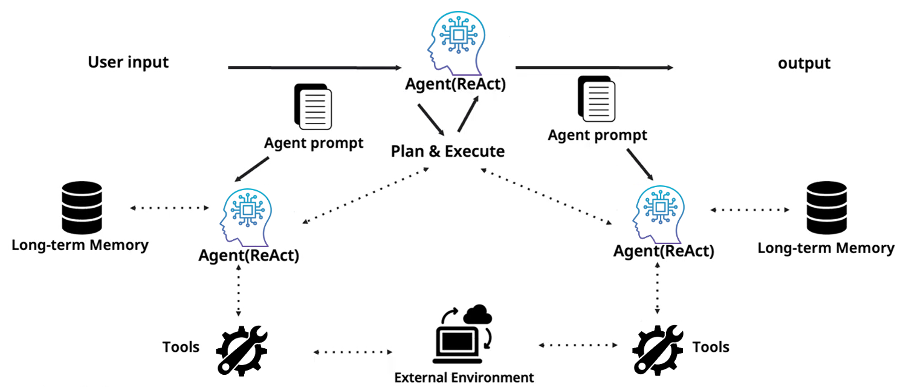
물론 멀티에이전트에도 고유한 과제가 있습니다. 에이전트 간 커뮤니케이션 오버헤드, 조율(Orchestration)의 복잡성, 디버깅의 어려움, 그리고 API 호출 비용 증가가 대표적입니다. 하지만 이러한 과제에도 불구하고, 최신 연구는 에이전트 수를 늘리는 것이 실질적인 성능 향상으로 이어진다는 것을 실험적으로 보여주고 있습니다.
그림 6. Neural Scaling Law. 모델의 성능(오차)이 모델 파라미터 수(N), 데이터셋 크기(D), 학습에 사용된 연산량(C)에 따라 멱법칙 형태로 개선됩니다[6].
그렇다면, 모델 자체를 키우는 것이 아니라 에이전트의 수와 협력 구조를 키우는 것도 비슷한 효과를 낼 수 있을까요?
2025년 ICLR에 게재된 Qian et al.의 논문은 이 질문에 대해 최초의 체계적인 답을 제시합니다[7]. 연구팀은 DAG(Directed Acyclic Graph) 기반의 MacNet이라는 멀티에이전트 협업 네트워크를 구축하고, 에이전트 수를 2⁰(=1)부터 2⁶(=64, mesh 네트워크에서는 1,000개 이상)까지 기하급수적으로 늘려가며 실험했습니다.
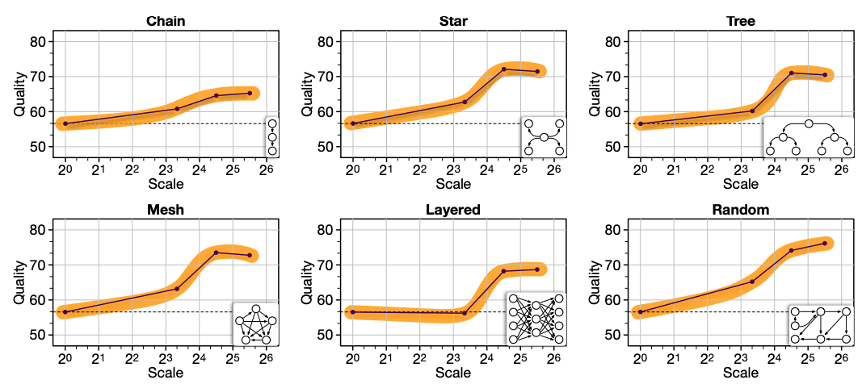
결과는 매우 인상적이었습니다. 에이전트 수가 늘어남에 따라 시스템 성능은 로지스틱 성장 패턴(logistic growth pattern)을 따랐습니다. 초기에는 천천히 성장하다가 급격한 향상 구간을 거쳐 포화점에 도달하는 S-커브 형태였습니다. 특히 주목할 만한 발견은, 이 collaborative emergence가 전통적인 neural emergence보다 더 일찍 발생한다는 것이었습니다. 연구팀은 이를 에이전트 스케일링이 상호 반성(interactive reflection)과 정제(refinement) 과정에서 다차원적 고려를 촉진하기 때문이라고 해석했습니다[7].
또 하나 중요한 발견은 토폴로지(topology)의 영향입니다. 불규칙 토폴로지가 규칙적인 것보다 일관되게 우수했습니다. 단순히 에이전트를 모두 연결하는 Full Connection 방식은 상호작용 횟수는 가장 많지만, 정보의 중복과 노이즈 때문에 오히려 성능이 떨어지거나 효율이 낮아질 수 있습니다. 상호작용의 횟수를 무작정 늘리는 것보다, 적절한 이웃 에이전트들과 깊게 소통하는 구조를 만드는 것이 성능 향상에 훨씬 효과적입니다[7].
그런데 2024년, 모델을 키우는 것과는 완전히 다른 축의 scaling이 발견됩니다. 모델을 더 크게 만드는 대신, 이미 만들어진 모델이 답변할 때 더 오래 생각하게 하면 성능이 올라간다는 것입니다. OpenAI의 o1 모델이 대표적입니다. o1은 바로 답을 내지 않고, 내부적으로 긴 chain-of-thought를 생성하며 여러 경로를 탐색하고, 자기 답변을 검토한 뒤 최종 응답을 내놓습니다. 이 "생각하는 시간"을 늘릴수록 AIME 같은 수학 추론 벤치마크에서 성능이 꾸준히 올라갑니다[8].
이것을 Test-time Compute Scaling이라고 부릅니다. 학습할 때 더 많은 연산을 투입하는 것(Pre-training Scaling)과 대비되는 개념으로, 추론할 때 더 많은 연산을 투입하는 것입니다. 비유하자면, 시험을 잘 보기 위해 (1) 더 오래 공부하는 방법과 (2) 시험 시간을 더 많이 주는 방법이 있는 것과 같습니다. 놀랍게도, 특정 조건에서는 작은 모델에 더 많은 "시험 시간"을 주는 것이 큰 모델을 한 번 호출하는 것보다 나을 수 있습니다[8].
멀티에이전트 시스템은 이 Test-time Compute Scaling의 가장 정교한 형태입니다. Best-of-N sampling처럼 같은 모델에게 여러 번 답을 시킨 뒤 가장 좋은 것을 고르는 것도 test-time compute의 일종이지만, 멀티에이전트 시스템은 여기서 한 발 더 나갑니다. 각 에이전트가 서로 다른 전문성을 가지고, 서로 다른 관점에서 문제를 바라보며, 독립적으로 검증하고, 이 과정에서 발생하는 추론 연산이 단순 반복이 아닌 구조화된 협업의 형태를 띱니다. 앞서 소개한 Collaborative Scaling Law[7]가 바로 이 "구조화된 추론"이 단순 반복보다 훨씬 효과적이라는 것을 실험적으로 보여준 것입니다.
이것이 플랫폼 설계에 의미하는 것
위의 발견들을 Agentria 같은 B2B 멀티에이전트 플랫폼의 관점에서 번역하면, 몇 가지 설계 원칙이 도출됩니다.
- 에이전트 수보다 토폴로지가 중요합니다. 고객이 에이전트를 설계할 때, 단순히 에이전트를 많이 만드는 것보다 어떤 구조로 연결하느냐가 결정적입니다. 플랫폼 차원에서 토폴로지 최적화를 지원하거나 권장 구조를 제시하는 것이 필요합니다.
- 포화점을 인지해야 합니다. Collaborative Scaling Law가 로지스틱 패턴을 따른다는 것은, 어느 시점 이후로는 에이전트를 추가해도 성능 향상이 미미해진다는 의미입니다. 이 포화점을 감지하고 사용자에게 피드백하는 메커니즘이 필요합니다.
마무리
싱글 프롬프트에서 멀티에이전트 시스템까지의 여정은 단순한 기술 진화가 아닙니다. LLM이라는 확률 모델의 근본적 특성에서 비롯되는 구조적 한계를 시스템 레벨에서 극복하려는 설계적 노력입니다.
정리하면, AI 성능을 올리는 축은 세 가지입니다. 모델 파라미터를 키우는 것(Model Scaling), 추론 시 더 오래 생각하게 하는 것(Test-time Compute Scaling), 그리고 에이전트의 수와 협업 구조를 키우는 것(Agent Scaling). 2025년 ICLR에서 제시된 Collaborative Scaling Law[7]는 세 번째 축이 단순한 직관이 아니라 실험적으로 검증된 원리임을 보여줍니다. 그리고 멀티에이전트 시스템은 두 번째와 세 번째 축이 교차하는 지점에 있습니다—추론 시점의 연산을 구조화된 협업으로 투입하는 것이니까요.
다음 글에서는 멀티에이전트 시스템을 실제로 설계할 때 필요한 구체적인 협업 전략(Cooperation, Competition, Coopetition)과 토폴로지, 커뮤니케이션 프로토콜, 그리고 MAS 평가 방법론에 대해 다루겠습니다.
References
[1] Wei et al., "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models," NeurIPS 2022.
[2] Lewis et al., "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks," NeurIPS 2020.
[3] Yao et al., "ReAct: Synergizing Reasoning and Acting in Language Models," ICLR 2023.
[4] Bengio et al., "Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks," NeurIPS 2015.
[5] Huang et al., "Large Language Models Cannot Self-Correct Reasoning Yet," ICLR 2024.
[6] Kaplan et al., "Scaling Laws for Neural Language Models," OpenAI, 2020.
[7] Qian et al., "Scaling Large Language Model-based Multi-Agent Collaboration," ICLR 2025.
[8] Snell et al., "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters," ICLR 2025.

