영상 면접 평가의 공정성, 점수 분포에서 학습한다
영상 면접 평가가 채용 전형을 가르는 단계까지 쓰이고 있습니다. 모델이 품은 편향은 점수에 그대로 실립니다. 제네시스랩 연구진이 공동 저자로 참여한 IEEE Access 2023 논문은 연속 점수와 멀티모달이라는 두 조건에서, 공정성을 학습 손실의 정규화항으로 직접 적용하는 방법을 제시합니다.

비대면 채용이 늘면서 자동 영상 면접 평가(AVI, Automated Video Interview)는 더는 보조 도구가 아닙니다. 지원자의 영상을 모델이 먼저 점수로 바꿉니다. 그 점수가 일정 기준을 넘어야 다음 전형으로 넘어갑니다. 모델이 품은 편향은 점수에 실려 의사결정 단계에도 그대로 반영됩니다.
문제는 기존의 공정성 연구가 이 맥락에 그대로 들어맞지 않는다는 점입니다. 공정성 ML 문헌의 대부분은 pass/fail 같은 이진 라벨과 정형화된 tabular 데이터를 전제로 쓰여 왔습니다[1][2]. 그러나 영상 면접에서 모델이 출력하는 값은 연속적인 점수입니다. 입력은 영상·음성·텍스트가 섞인 멀티모달 데이터입니다. 아마존이 이력서 스크리닝 시스템을 철수한 사건처럼, 채용 AI의 편향은 현실에서 이미 여러 번 문제로 드러났습니다[3]. 따라서 AVI에서는 무엇을, 어떻게 공정하게 만들 것인지에 대한 정의부터 새로 짜야 했습니다.
제네시스랩 연구진이 공동 저자로 참여한 논문이 이 문제를 본격적으로 다뤘습니다. IEEE Access 2023에 게재된 이 연구는 연속 점수 예측이라는 AVI 고유의 조건에서 멀티모달 공정성을 학습하는 방법을 제시합니다.
논문: Fairness-Aware Multimodal Learning in Automatic Video Interview Assessment
저자: Changwoo Kim, Jinho Choi (Genesis Laboratory·KAIST), Jongyeon Yoon, Daehun Yoo (Genesis Laboratory), Woojin Lee
학회/저널: IEEE Access, Vol. 11, 2023
원문: https://doi.org/10.1109/ACCESS.2023.3325891
문제와 접근
AVI의 공정성 문제는 세 가지 조건이 겹쳐 있습니다.
첫째, 연속 점수와 사후 임계값입니다. 모델은 0에서 1 사이의 연속 점수 Ŷ를 예측합니다. 임계값 τ는 이후 채용팀이 정합니다. τ가 고정되지 않으므로 "특정 임계값에서 공정하다"는 주장은 의미가 흐립니다. 특정 임계값에 의존하지 않는 공정성 정의가 필요합니다.
둘째, 멀티모달 입력의 복잡도입니다. 선형·볼록 최적화에 기반한 기존 공정성 알고리즘[4][5]은 tabular 데이터에서는 잘 작동했습니다. 그러나 영상·음성·텍스트가 섞인 고차원 입력으로 확장하기는 어렵습니다.
셋째, 공정성과 정확도의 상충 관계입니다. 공정성을 강제하면 전체 정확도가 떨어지기 쉽습니다. 운영 상황에 따라 어느 쪽에 무게를 둘지 조절할 수 있어야 합니다.
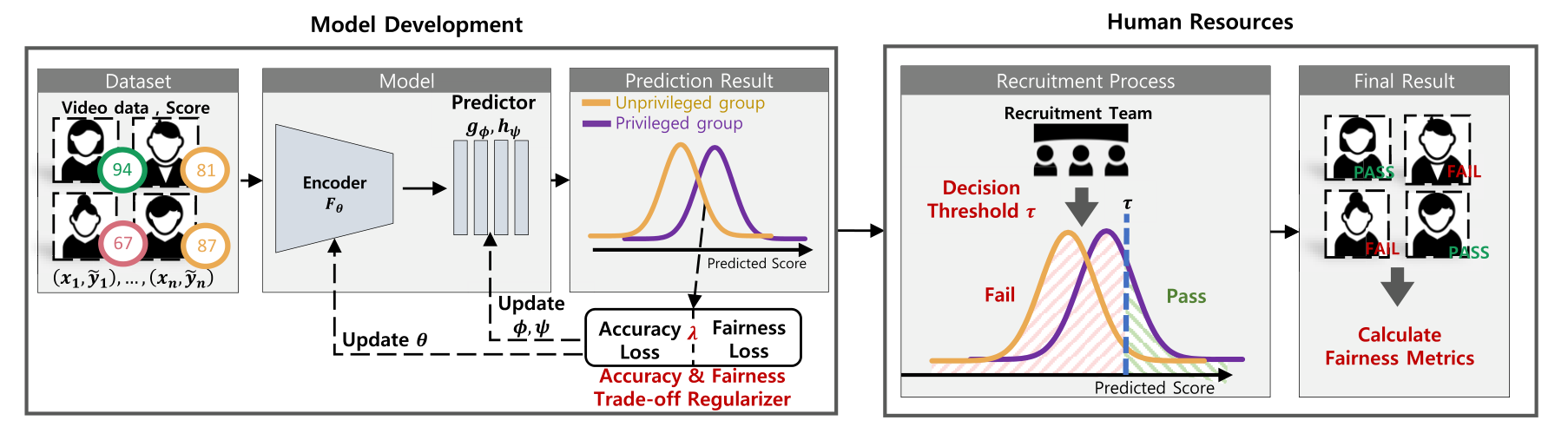
논문은 세 조건을 동시에 충족하는 프레임워크를 제안합니다. 핵심은 두 가지입니다. (1) 공정성 지표를 임계값에 의존하지 않는 형태인 SPDD(Strong Pairwise Demographic Disparity)로 바꿉니다. (2) SPDD가 두 민감 그룹의 점수 분포 사이 1-Wasserstein distance와 수식적으로 연결된다는 사실을 이용해, Wasserstein distance 자체를 학습 중 정규화항으로 넣습니다. 정확도와 공정성의 균형은 하이퍼파라미터 λ_W 하나로 조절됩니다.
방법
연속 점수용 공정성 지표 SPDD
가장 널리 쓰이는 공정성 지표인 Demographic Parity(DP)는 임계값이 고정된 상태에서 정의됩니다.
DP(g_τ) = |Pr(Ŷ=1 | S=1) − Pr(Ŷ=1 | S=0)|
여기서 S는 민감 속성(논문 실험에서는 gender), g_τ는 임계값 τ로 만드는 이진 분류기입니다. τ가 바뀌면 DP 값도 바뀝니다. 임계값이 운영 단계에서야 정해지는 AVI에서는 τ에 의존하는 지표 하나만으로는 부족합니다.
저자들은 τ를 uniform distribution에서 샘플링한 뒤 DP를 τ에 걸쳐 평균낸 SPDD를 제안합니다.
SPDD(η) = E_τ~U([0,1]) [ ΔDP(g_τ) ]
어떤 τ를 고르든 DP 차이가 평균적으로 작다면 공정한 모델이라는 뜻입니다.
Wasserstein distance와의 연결
핵심 아이디어는 SPDD가 민감 그룹별 점수 분포 사이의 1-Wasserstein distance와 같다는 사실에서 출발합니다(논문 Eq. 10~11).
Wasserstein distance는 직관적으로 "한 점수 분포를 다른 점수 분포 모양으로 옮길 때 필요한 최소 작업량"입니다. 흙더미 두 개가 있을 때 한쪽을 다른 쪽 모양으로 만들려면 얼마만큼의 흙을 얼마나 옮겨야 하는지를 재는 셈입니다. 민감 그룹 사이 점수 분포를 이 거리로 맞추면, 어떤 임계값을 고르든 두 그룹의 pass 비율 차이가 전반적으로 줄어듭니다.
결과적으로 1-Wasserstein distance를 줄이는 일이 SPDD를 줄이는 일과 같습니다. 이 값을 손실 함수에 정규화항으로 직접 넣으면, 모델은 학습 과정에서 민감 그룹 간 점수 분포를 스스로 정렬합니다.
멀티모달 인코더와 적대적 학습
영상·음성·텍스트 세 모달리티는 각자 다른 인코더를 거쳐 표현 벡터로 바뀝니다. 영상은 2D CNN과 LSTM, 음성은 MFCC 위에 LSTM, 텍스트는 pre-trained BERT에 FC layer를 얹습니다. 세 표현을 이어 붙여 공통 잠재공간 Z를 만듭니다.
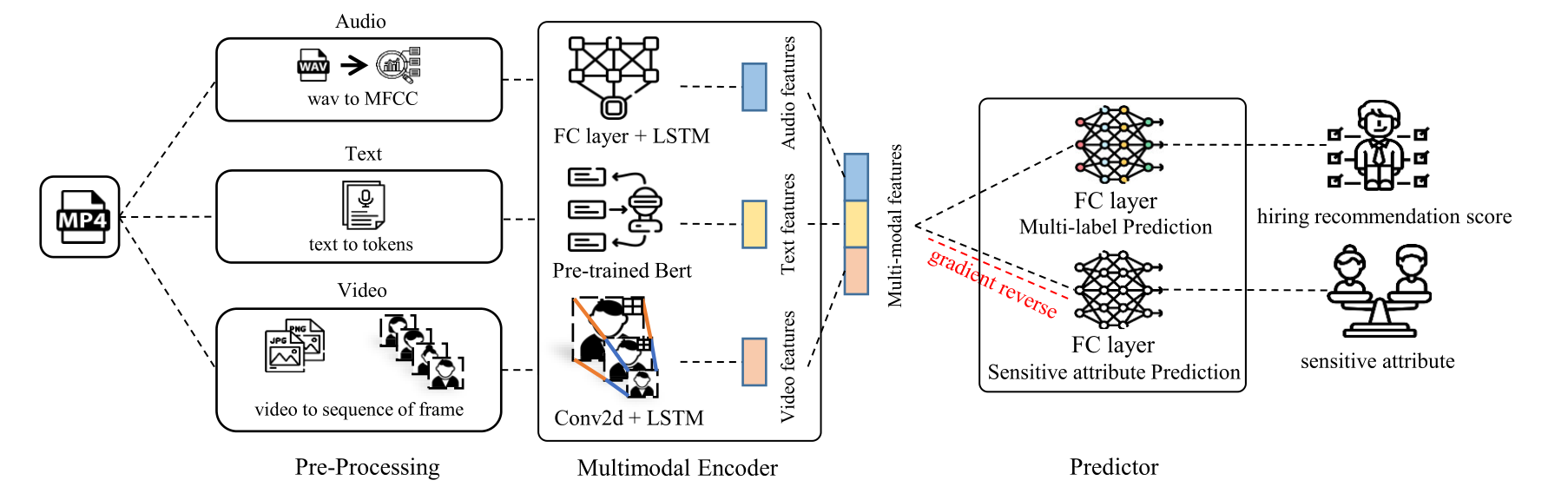
Z 위에서 두 개의 헤드가 학습됩니다. regressor gφ는 점수 Ŷ를 예측합니다. adversary hψ는 민감 속성 S를 예측합니다. 인코더는 gradient reversal layer로 adversary의 손실을 일부러 키우는 방향으로 학습됩니다[6]. 즉 "민감 속성을 맞추기 어렵게 만드는 표현"을 찾습니다.
전체 손실 함수
두 장치가 하나의 목적 함수로 묶입니다.
L_Reg(X, Ỹ) = E[ ‖g(F(X)) − Ỹ‖² ] + λ_W · L_W
L_Adv(X, S) = D_{θ,ψ}(X, S)
min_{φ,ψ} L_Reg(X, Ỹ) + L_Adv(X, S)
min_θ L_Reg(X, Ỹ) − L_Adv(X, S)
첫 줄의 MSE 항은 점수 예측 정확도를 맡고, λ_W · L_W는 Wasserstein distance를 통한 공정성 정규화항입니다. 아래 두 줄은 encoder/regressor/adversary의 min-max 업데이트 순서를 보여줍니다. λ_W를 키우면 공정성이 강해집니다. 줄이면 정확도가 좋아집니다.
왜 이 두 장치를 같이 써야 할까요. Wasserstein 항만으로는 "예측 점수 분포"를 정렬할 뿐, 표현 Z 자체에 민감 속성이 남아 있을 수 있습니다. adversary는 Z 수준에서 민감 속성 정보의 영향을 줄입니다. 두 장치는 서로 다른 층위에서 공정성을 강제하기 때문에 함께 써야 의미가 있습니다. 이 점은 뒤의 표현 공간 분석에서 다시 확인됩니다.
결과
데이터셋과 편향 주입
실험은 두 가지 데이터셋에서 이뤄졌습니다.
- HR dataset: 한국어 면접 영상 3,000여 건. 지원자가 90초 안에 사전 질문에 답합니다. 20년 이상 경력의 면접 전문가 3인이 준 hiring recommendation score의 평균이 라벨입니다[7]. 민감 속성은 gender.
- FI dataset: First Impressions(CVPR 2017 Chalearn Lab 챌린지). 영어권 YouTube 영상 10,000건. 역시 민감 속성은 gender.
핵심 실험 설계는 편향의 강도를 인위적으로 조절한다는 점입니다. α라는 지표를 정의해 고득점 그룹에서 priv/unpriv 비율을, 저득점 그룹에서 unpriv/priv 비율을 한쪽으로 치우치게 조정합니다. α=2면 고득점 그룹의 priv 비율이 67%, α=3이면 75%, α=4면 80%로 커집니다.
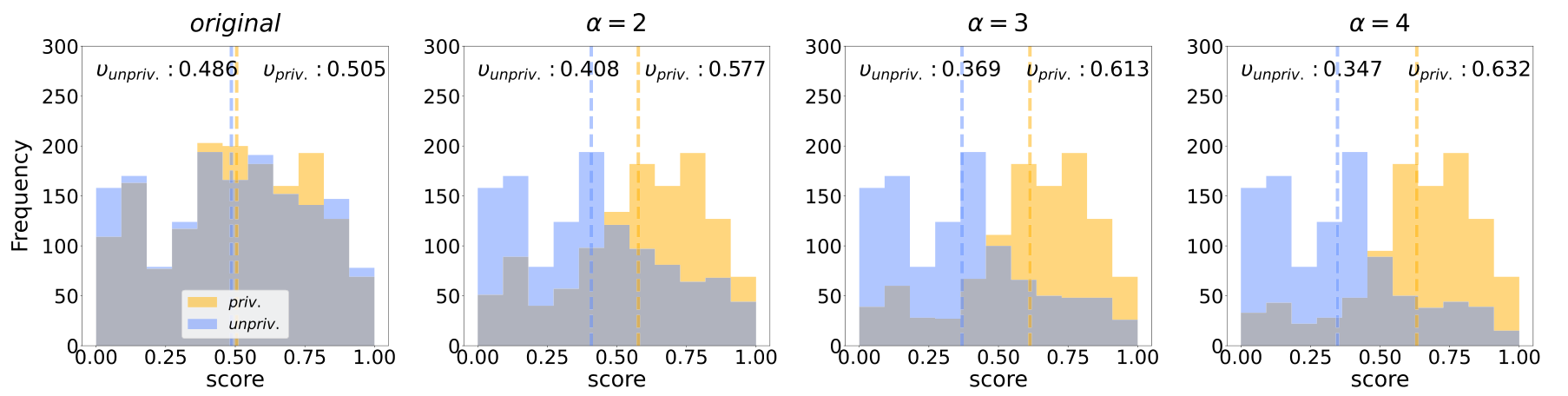
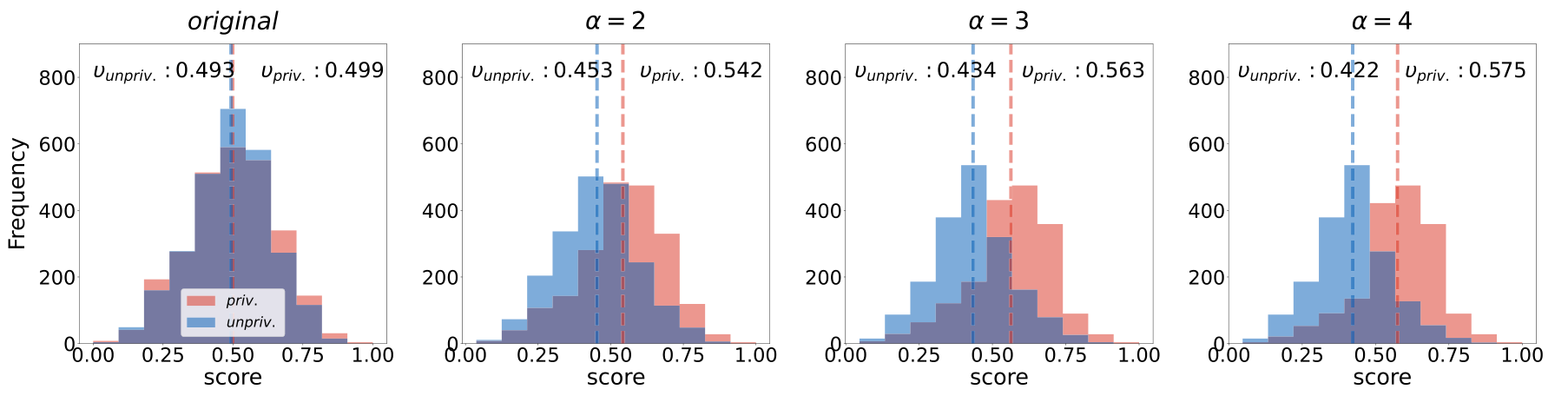
테스트셋은 민감 속성이 고르게 분포된 상태를 유지해, 학습 데이터의 편향이 예측에 얼마나 그대로 옮겨가는지 볼 수 있게 했습니다.
정량 결과
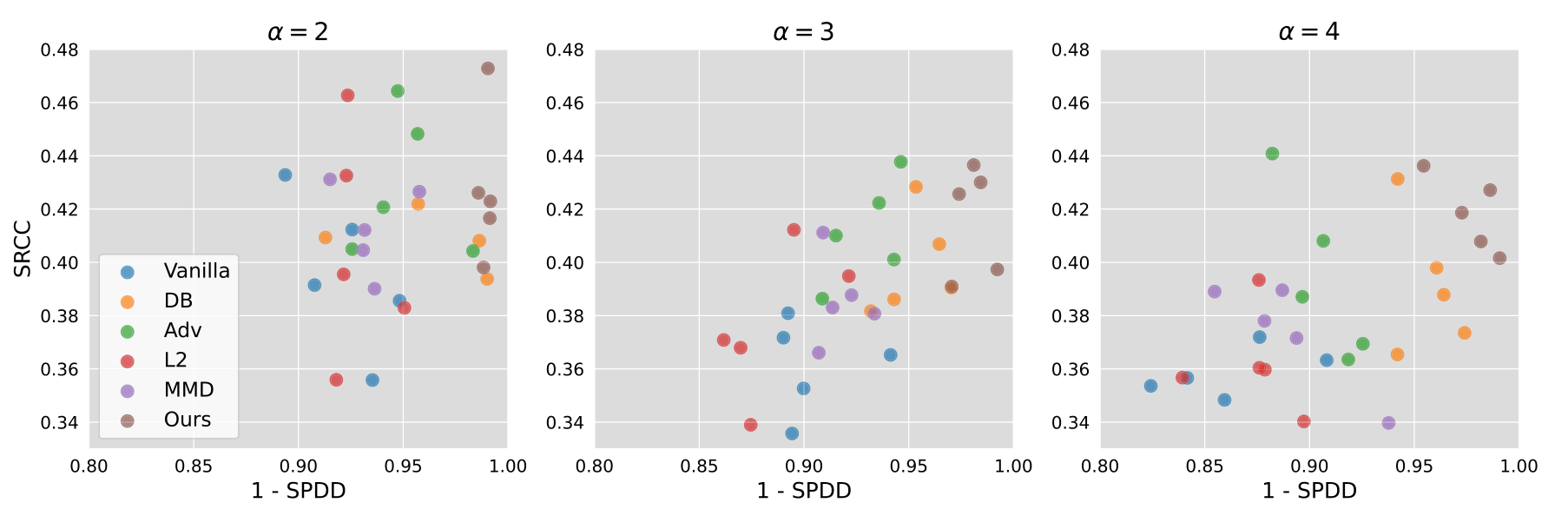
비교 대상 베이스라인은 다섯 가지입니다. Vanilla(공정성 제약 없음), Data Balancing(DB), Adversarial training(Adv)[6], Euclidean L2 distance, MMD(Maximum Mean Discrepancy)[8]. 평가 지표는 예측 성능 지표(PCC, SRCC)와 공정성 지표(SPDD, SPEO) 네 가지입니다.
HR dataset, α=4 구간의 수치는 다음과 같습니다.
| Method | PCC | SRCC | SPDD | SPEO |
|---|---|---|---|---|
| Vanilla | 0.408 | 0.359 | 0.138 | 0.142 |
| DB | 0.434 | 0.391 | 0.043 | 0.041 |
| Adv | 0.433 | 0.394 | 0.094 | 0.098 |
| L2 | 0.407 | 0.362 | 0.127 | 0.129 |
| MMD | 0.420 | 0.374 | 0.110 | 0.104 |
| Ours | 0.458 | 0.418 | 0.020 | 0.016 |
학습 데이터를 가장 불공정하게 만든 조건인 α=4에서 Vanilla의 SPDD는 0.138, 제안 방법은 0.020입니다. 공정성뿐 아니라 SRCC도 0.359에서 0.418로 올랐습니다. 공정성과 정확도의 상충 관계가 상식처럼 알려져 있는데, 이 구간에서는 공정성뿐 아니라 PCC·SRCC에서도 베이스라인을 앞섭니다. 다른 구간과 FI dataset에서는 공정성 우위가 더 뚜렷합니다. 성능 지표는 최상위에 근접하거나 동률입니다.
α=2, 3 구간에서도 방향은 같습니다. HR dataset의 Ours SPDD는 α=2에서 0.011, α=3에서 0.020으로 유지됩니다. FI dataset에서도 α=4일 때 SPDD 0.051(Vanilla 0.078), SRCC 0.518(Vanilla 0.500)로 우위를 보입니다.
표현 공간에서 본 공정성
정량 지표 외에 latent representation Z를 PCA로 2차원에 투영해 priv/unpriv centroid 사이 거리를 봤습니다. Vanilla와 Adv, DB에서는 두 그룹의 표현이 뚜렷이 갈라지는 반면, 제안 방법에서는 centroid 거리가 가장 작습니다. 즉 점수 수준뿐 아니라 표현 수준에서도 민감 속성 정보가 희석되어 있음을 보여줍니다.
λ_W로 조절되는 상충 관계
공정성과 정확도는 λ_W 하나로 연속적으로 조절됩니다.
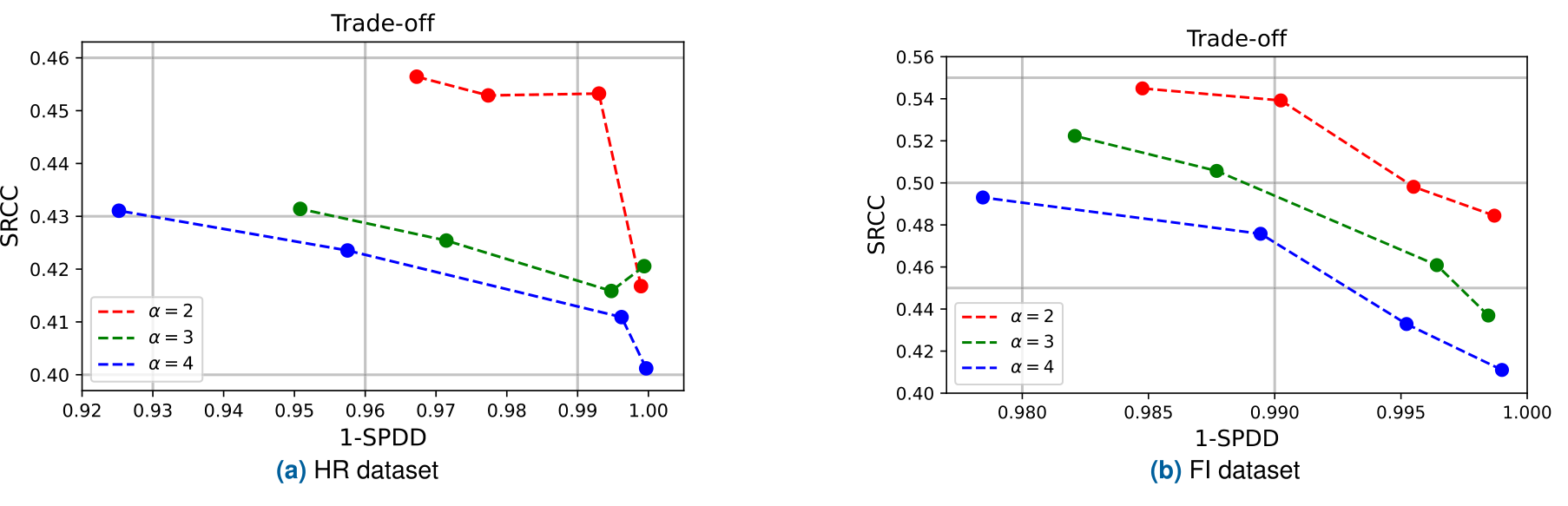
"어느 정도까지 공정성을 강제할 것인가"가 도메인·운영 정책에 따라 다르다면, λ_W 값을 바꿔 재학습하는 것만으로 여러 균형점을 얻을 수 있다는 점이 실무적으로 유용합니다.
viewinterHR에서의 의미
제네시스랩의 viewinterHR은 영상 면접을 자동으로 평가하고 채용팀에 점수를 제공합니다. 이 논문의 방법은 viewinterHR이 다루는 입력(영상·음성·텍스트)과 출력(연속 점수)의 구조와 동일합니다.
세 가지 측면에서 바로 맞물립니다. 첫째, 채용팀이 이후에 정하는 임계값 τ와 무관하게 공정성이 유지되어야 한다는 조건이 현장 운영과 일치합니다. 둘째, gender 외의 민감 속성(연령 등)으로 확장하려면 adversary의 분류 대상만 바꾸면 됩니다. 셋째, λ_W 하나로 도메인·고객사 정책에 따라 공정성을 어느 정도 강제할지 정합니다. PCA centroid 거리와 SPDD 수치를 함께 남기면, 평가가 왜 공정한지에 대한 설명이 점수와 함께 제공됩니다.
이 방법은 IEEE Access에 게재되며 학계의 검토를 거쳤습니다.
한계와 앞으로의 과제
논문에서 언급한 제약은 두 가지입니다.
첫째, 학습 단계에서 민감 속성 라벨이 있어야 합니다. EU GDPR처럼 개인정보 규제가 강한 환경에서는 이 전제를 맞추기 어렵습니다. 민감 속성을 직접 쓰지 않고도 공정성을 유지하는 방향은 후속 연구의 몫으로 남습니다.
둘째, 검증은 비동기 영상 면접(AVI) 한 방식에서만 이뤄졌습니다. 실시간 면접, 게임 기반 평가, 챗봇 면접처럼 방식이 달라지면 데이터 분포도 달라집니다. Wasserstein 정규화와 adversary라는 골격을 그대로 쓸 수 있을지, 새로 짜야 할지는 다시 확인해야 할 문제입니다.
그럼에도 핵심 뼈대는 남습니다. 연속 점수와 멀티모달이라는 조건에서도 공정성을 학습 손실의 정규화항으로 직접 적용할 수 있습니다. λ_W 하나로 정확도와의 균형점도 조절할 수 있습니다. 이때 λ_W는 단순한 하이퍼파라미터가 아니라 조직이 어디까지 공정성을 강제할지 정하는 정책 변수로 다뤄야 합니다. 공정성은 선언이 아니라 분포 설계의 결과입니다.
References
[1] Feldman, M.; Friedler, S. A.; Moeller, J.; Scheidegger, C.; Venkatasubramanian, S. Certifying and Removing Disparate Impact. In Proc. 21st ACM SIGKDD Int. Conf. Knowledge Discovery and Data Mining, 2015, pp. 259–268. https://doi.org/10.1145/2783258.2783311
[2] Calders, T.; Verwer, S. Three Naive Bayes Approaches for Discrimination-Free Classification. Data Mining Knowl. Discovery 2010, 21 (2), 277–292. https://doi.org/10.1007/s10618-010-0190-x
[3] Dastin, J. Amazon Scraps Secret AI Recruiting Tool That Showed Bias Against Women. In Ethics of Data and Analytics; Auerbach Publications, 2018; pp. 296–299.
[4] Zafar, M. B.; Valera, I.; Rogriguez, M. G.; Gummadi, K. P. Fairness Constraints: Mechanisms for Fair Classification. In Proc. Artif. Intell. Stat., 2017, pp. 962–970.
[5] Calmon, F.; Wei, D.; Vinzamuri, B.; Ramamurthy, K. N.; Varshney, K. R. Optimized Pre-Processing for Discrimination Prevention. In Proc. Adv. Neural Inf. Process. Syst., 2017.
[6] Ganin, Y. et al. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2016, 17 (1), 2030–2096.
[7] Naim, I.; Tanveer, M. I.; Gildea, D.; Hoque, M. E. Automated Prediction and Analysis of Job Interview Performance. In Proc. 11th IEEE Int. Conf. Autom. Face Gesture Recognit. (FG), 2015, Vol. 1, pp. 1–6. https://doi.org/10.1109/FG.2015.7163127
[8] Schumann, C.; Wang, S.; Beutel, A.; Chen, J.; Qian, H.; Chi, E. H. Transfer of Machine Learning Fairness Across Domains. arXiv:1906.09688, 2019.

