Consistent recruitment document assessment, how agents structured assessment criteria
AI-powered candidate screening that turns your JD and talent profile into structured evaluations, competency scores, and interview questions — automatically.

Every recruiter knows the feeling. It's peak hiring season, and you're reviewing hundreds of cover letters on your own.
The first fifty are manageable — you read each one against a clear set of criteria. But somewhere past the hundredth, the words start to blur. By the hundred-and-fiftieth, the impressions left by earlier candidates begin seeping into how you read the one in front of you. At an average of ten minutes per application, two hundred cover letters is two full days of work. Maintaining consistent judgment from the first file to the last is extraordinarily difficult.
Fatigue, however, is only part of the problem. The deeper issue is structural: qualitative evaluation is, by nature, dependent on human judgment.
Résumés can be partially quantified once you establish criteria — years of experience, relevant roles, specific skills. Cover letters are a different matter. Whether a candidate's motivation is genuine, whether their problem-solving experience has real depth, whether this person is the right fit for your organization — these judgments hinge on the evaluator's own frame of reference, and on how they happen to be feeling that day. It is not uncommon for the same cover letter to clear the bar in spring and fall short in autumn, simply because the reviewers were different people.
Some organizations respond by investing in evaluator training and standardized rubrics. Yet hiring panels change from season to season, and as volume grows, training itself becomes a bottleneck. As long as evaluation criteria live only in a document, dependency on individual judgment never goes away.
Three problems keep recurring.
- Physical constraints. The number of applicants and the evaluation resources available do not scale together. Double the hiring volume, and you need double the review time — but the number of people on your team stays the same.
- The subjectivity of qualitative assessment. Cover letter evaluation is shaped by each reviewer's experience and interpretive lens. Even when a shared rubric exists, people read it differently.
- The disconnect between screening and interviews. Insights gathered during document review rarely carry over into interview preparation. Interviewers are left to re-assess a candidate's competencies from scratch, without the benefit of what the screening process already uncovered.
The common thread: judgment criteria and context are locked inside individuals. When evaluators change, standards shift. When volume scales, consistency breaks down. This is the structural vulnerability that an AI agent is built to address.
Introducing the Recruitment Screening Agent
A pipeline that gives structure to qualitative judgment
The question we started with was this: How do you bring structure to the qualitative evaluation of cover letters?
Simply extracting keywords or classifying sentences does not produce meaningful assessments. To determine how well a candidate's experiences connect to the role, or whether their approach to problem-solving aligns with your organization's talent profile, the evaluation criteria themselves must first be structured.
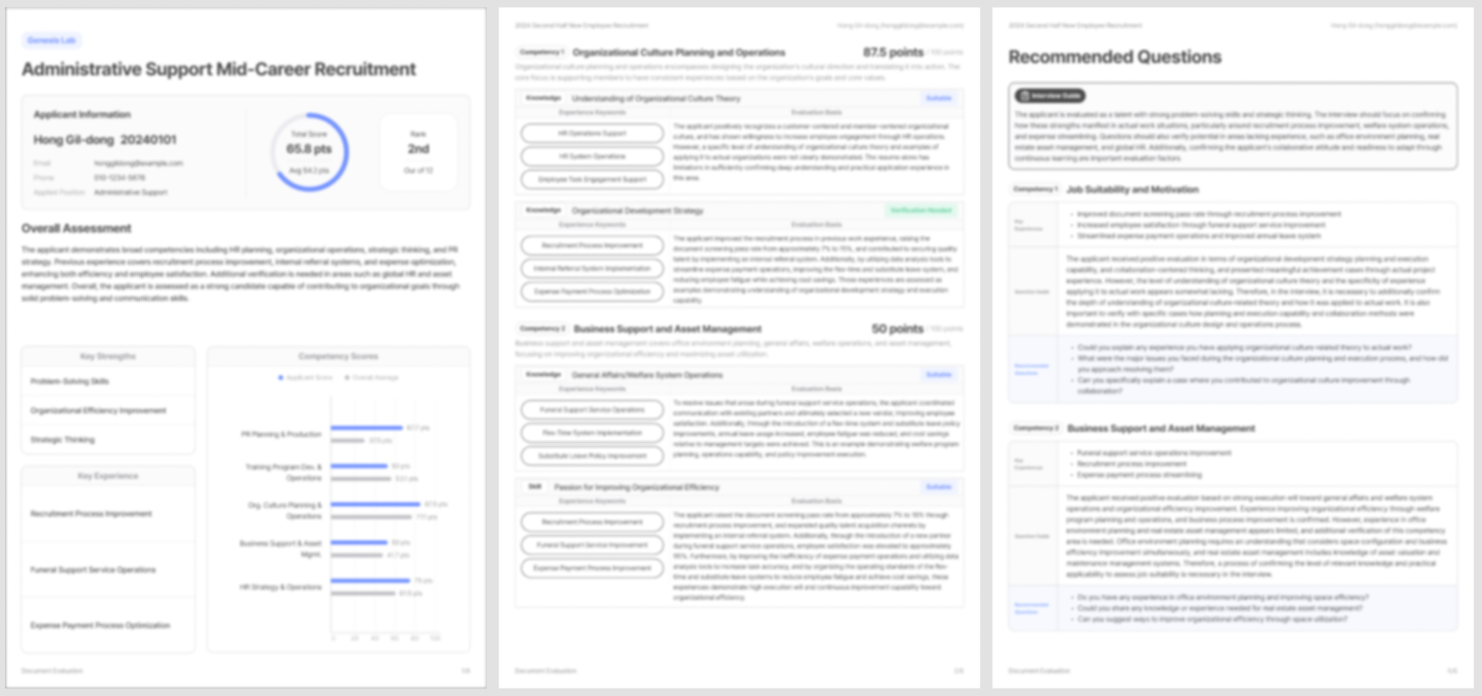
Before designing the agent, we undertook the work of decomposing evaluation criteria into discrete, assessable components. When a job description and talent profile are entered, an analysis agent structures the evaluation framework. Résumés and cover letters are parsed and mapped to each criterion. The evaluation agent then generates scores by competency, accompanied by a written explanation of which experiences informed each judgment and why. A final interview agent takes these results and produces a candidate-specific interview guide, complete with recommended questions.
Each agent can be improved or replaced independently, and any issues can be traced to the precise stage where they occurred. This architecture runs on Agentria's modular platform and is delivered through ViewinterHR, a service already adopted by a wide range of large enterprises and public institutions.
Processing time per candidate: under one minute.
"Can AI really read a cover letter properly?"
This is invariably the first question organizations ask when considering AI-assisted screening — and it is the right question to ask. Concerns about fairness and bias in AI hiring systems have been well documented. Amazon's internal recruiting tool, developed from 2014, was found to systematically score down résumés containing language associated with women; the project was discontinued in 2017. The opacity of algorithmic decision-making — the fact that candidates cannot see how they were evaluated — remains a persistent concern.
Our response to these challenges is built into how the system works. Every judgment the agent makes is accompanied by its reasoning. You can see exactly which passage from a cover letter was mapped to which competency criterion, and why that mapping was made. These are not black-box outputs — they are transparent, reviewable results that a human evaluator can examine and understand.
The ability of AI to read a cover letter properly depends entirely on the clarity and rigor of the evaluation structure behind it. When that structure is verifiable, the evaluation becomes trustworthy.
Explainability is not optional. It is a prerequisite for real-world deployment.
A structure that works for any company, any role
This is not a system built for one organization. Through Agentria, we have designed a framework that can be applied across any company and any job function — and we operate it through the ViewinterHR service. It is a proven pipeline already running in production at major enterprises and public sector organizations.
For companies adopting ViewinterHR, the process begins with a single input: the job description and talent profile for the role you are hiring for. The analysis agent structures the evaluation criteria from there, and the full pipeline — through screening, assessment, and interview preparation — takes over.
Whether the role is in technology or sales, whether you are hiring for entry-level or experienced professionals, the evaluation criteria adapt to the position while the underlying structure remains robust. There is no need to rebuild your evaluation framework every hiring season. The structure has already been validated — all you need to do is apply your organization's own standards to it.
Next hiring season, cover letters will still arrive in the hundreds or thousands. What changes is this: the criteria applied to the very first application will be exactly the criteria applied to the very last. No earlier candidate's impression will color your reading of a later one. And the reasoning behind every judgment will be clearly visible in writing.
This is not about replacing the recruiter's judgment. It is about ensuring that judgment is exercised on a stable, consistent foundation — so that your team's attention can go where it matters most.

