일관된 채용 서류 평가, 에이전트로 평가 기준을 구조화한 방법
JD와 인재상을 기반으로 평가 기준을 구조화하고, 지원자별 역량 점수·평가 근거·면접 추천 질문까지 자동 생성합니다.

채용 담당자라면 한 번쯤 겪는 상황이 있습니다. 자소서 수백 건을 혼자 검토해야 하는 공채시즌입니다.
처음 50건은 명확한 기준대로 읽습니다. 서류가 100건을 넘어가면 문장이 눈에 들어오지 않기 시작합니다. 150건을 넘어가는 시점에는 앞서 읽은 지원자의 인상이 현재 평가 중인 지원자의 서류에 슬며시 섞입니다. 한 건에 평균 10분이 걸린다고 하면, 200건은 이틀치 근무 시간입니다. 그 시간 동안 처음부터 끝까지 같은 기준을 유지하기는 매우 어렵습니다. 피로만이 문제가 아닙니다. 정성 평가가 본질적으로 사람의 판단에 의존하는 구조라는 점입니다.
이력서는 기준을 세우면 어느 정도 정량화가 됩니다. 경력 연수, 직무 관련 경험, 보유 스킬 — 기준이 될 항목이 명확합니다. 하지만 자기소개서는 다릅니다. 지원 동기가 진심인지, 문제 해결 경험에 깊이가 있는지, 이 지원자가 우리 조직에 맞는지, 이 결정은 텍스트를 읽는 사람의 기준과 그날의 컨디션에 달려 있습니다. 같은 자기소개서로도 상반기에 지원하면 합격하고, 하반기에 지원하면 탈락하는 일이 실제로 벌어집니다.
혹자는 "그건 평가자 교육의 문제 아닌가요?" 라고 말하기도 합니다. 실제로 많은 조직이 평가 가이드를 만들고 평가자 교육을 시도했습니다. 하지만 채용 시즌마다 평가자 구성이 바뀌고, 규모가 커질수록 교육 자체에 병목이 생깁니다. 평가 기준이 문서 안에만 있는 한, 사람에 대한 의존은 끊기지 않습니다.
세 가지 문제가 반복됩니다.
- 물리적 한계: 지원자 수와 평가 리소스는 비례하지 않습니다. 채용 규모가 두 배가 되면 검토 시간도 두 배가 필요하지만, 담당자 수는 그대로입니다.
- 정성 평가의 주관성: 자기소개서 평가는 평가자의 경험과 판단 기준에 좌우됩니다. 같은 기준을 공유해도 해석은 사람마다 다릅니다.
- 면접 연결의 단절: 서류 평가 결과가 면접 준비로 이어지지 않습니다. 어떤 역량을 검증해야 하는지 면접관이 다시 처음부터 판단해야 합니다.
공통점이 있습니다. 판단의 기준과 맥락이 사람에게 묶여 있습니다. 평가자가 바뀌면 기준이 흔들리고, 규모가 커지면 일관성이 무너집니다. 에이전트가 해결해야 하는 것은 바로 이 구조적 취약성입니다.
채용 서류 평가 에이전트, 어떻게 달라지는가
정성 판단을 구조화하는 파이프라인
우리가 처음 마주한 질문은 이것이었습니다. "자기소개서의 정성 평가를 어떻게 구조화할 수 있을까?"
단순히 키워드를 추출하거나 문장을 분류하는 방식으로는 의미 있는 평가가 나오지 않습니다. 자기소개서에 담긴 경험이 직무와 얼마나 연결되는지, 문제 해결 방식이 우리 조직의 인재상에 부합하는지 판단하려면, 먼저 평가 기준 자체가 구조화되어야 합니다.
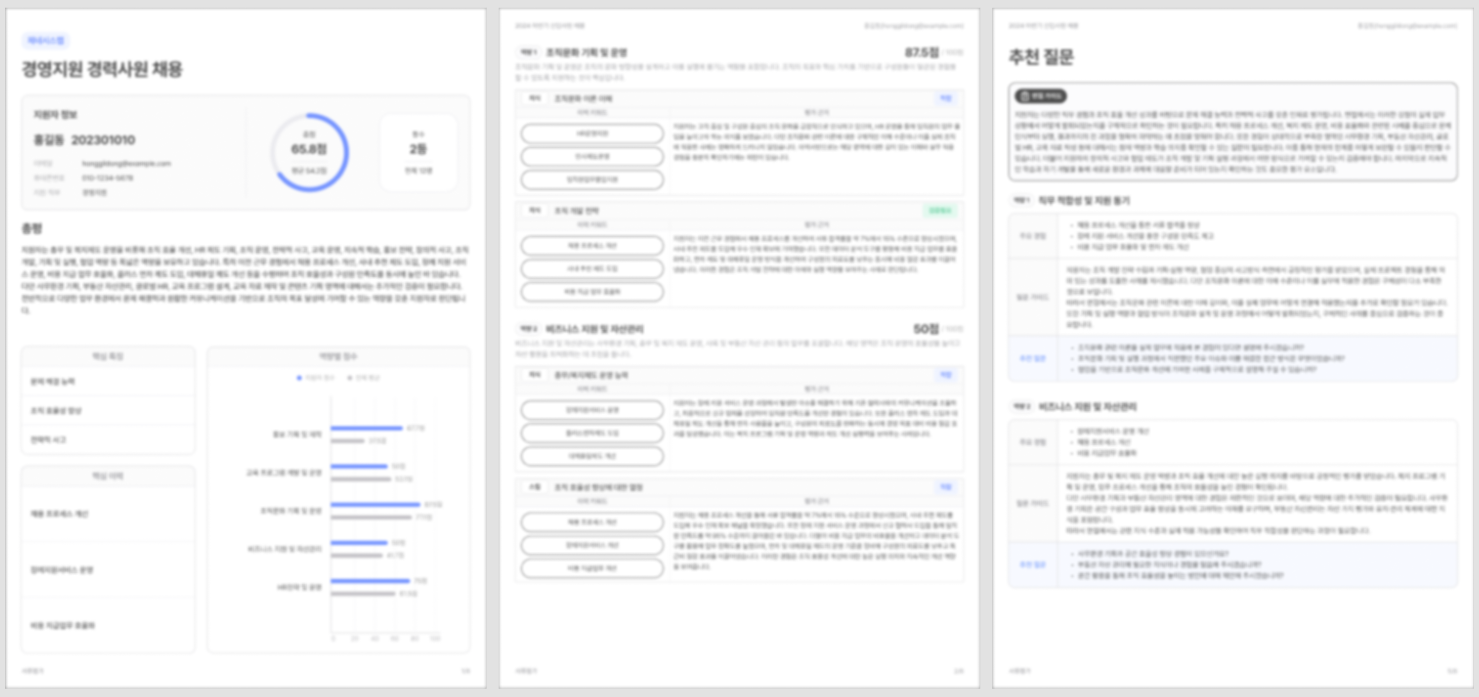
그래서 에이전트를 설계하기 전에, 우리는 평가 기준을 항목으로 분해하는 작업을 먼저 수행했습니다. JD와 인재상을 입력하면 분석 에이전트가 평가 항목을 구조화합니다. 이력서와 자기소개서는 파싱되어 각 평가 항목에 맵핑됩니다. 평가 에이전트는 역량별 점수와 함께 자기소개서의 어떤 경험이 어떤 기준에 근거해 판단됐는지를 텍스트로 생성합니다. 면접 에이전트는 이 결과를 바탕으로 지원자별 면접 가이드와 추천 질문을 만듭니다.
각 에이전트는 독립적으로 개선하거나 교체할 수 있습니다. 어느 단계에서 문제가 발생했는지 정확히 추적할 수 있습니다. 이 구조는 Agentria의 모듈형 아키텍처 위에서 작동합니다. 자사의 뷰인터HR에서 서비스되고 있으며, 많은 대기업과 공공기관에서 채택하여 운영 중입니다.
지원자당 처리 시간은 최대 1분 수준입니다.
"AI가 자소서를 제대로 읽을 수 있나요?"
AI 평가 도입을 검토하는 조직이 가장 먼저 묻는 질문입니다. 실제로 AI 채용 시스템의 공정성과 편향 문제는 여러 차례 논란이 된 바 있습니다. 아마존은 2014년 개발을 시작한 채용 AI가 여성 관련 단어가 포함된 이력서에 낮은 점수를 주는 편향을 드러냈고, 결국 2017년 해당 서비스를 폐기했습니다. 알고리즘이 어떻게 작동하는지 지원자가 알 수 없다는 불투명성 문제도 계속 제기됩니다. 이처럼, AI가 정성적 판단을 대체할 수 있는가에 대한 의문은 반드시 풀어내야 할 과제였습니다.
우리가 이 문제에 접근한 방식은 다음과 같습니다. 에이전트가 판단한 결과는 반드시 근거와 함께 제공됩니다. 자기소개서의 어떤 문장이 어떤 역량 항목에 맵핑됐는지, 그 판단의 이유가 무엇인지를 텍스트로 확인할 수 있습니다. 블랙박스 결과가 아니라, 사용자가 납득할 수 있도록 공개되는 결과입니다. AI가 자소서를 읽는다는 것은 평가 방식이 명확하게 구조화되어 있다는 의미입니다. 그 구조가 검증 가능할 때, 비로소 신뢰할 수 있는 평가가 됩니다.
설명 가능한 AI는 선택 사항이 아닙니다. 현장에 적용하기 위한 전제 조건입니다.
어떤 기업, 어떤 직무에도 적용되는 구조
이 에이전트는 특정 기업만을 위해 만든 시스템이 아닙니다. Agentria 를 통해 어떤 기업, 어떤 직무에도 적용되는 구조를 설계하였고, 이를 뷰인터HR 서비스로 운영하고 있습니다. 이미 여러 대기업과 공공기관에서 운영 중인 믿을 수 있는 파이프라인입니다.
뷰인터HR을 도입한 기업이 해야 할 일은 하나입니다. 채용하려는 직무의 JD와 인재상을 입력하는 것입니다. 분석 에이전트가 평가 기준을 구조화하고, 이후 평가·면접 준비까지의 파이프라인이 작동합니다. IT 직군이든 영업직군이든, 신입 채용이든 경력 채용이든 — 직무가 달라짐에 따라 평가 기준을 유연하게 적용하되, 구조는 견고하게 유지됩니다.
이제 채용 시즌마다 평가 기준을 새로 만들지 않아도 됩니다. 이미 검증된 구조 위에서, 우리 조직의 기준을 적용하기만 하면 됩니다.
다음 채용 시즌에도 자기소개서는 수백, 수천 건씩 쌓일 겁니다. 달라지는 건 첫 번째 지원자의 서류를 읽을 때도, 마지막 지원자의 서류를 읽을 때도, 처음부터 끝까지 같은 평가 기준을 유지할 수 있다는 점입니다. 앞서 읽은 지원자의 인상이 섞이지 않고, 판단 근거는 텍스트로 명확하게 확인할 수 있습니다.
채용 담당자의 판단을 대체하는 게 아닙니다. 흔들리지 않는 기준 위에서 더 중요한 판단에 집중할 수 있게 됩니다.

