어텐션 기반 LSTM을 이용한 미지의 변화 패턴에 강인한 특징 표현 학습
본 논문은 attentive mode variational LSTM을 통해 입력 정보를 task-relevant 특징과 task-irrelevant 특징으로 분리하여 unseen mode of variation에 강인한 시공간 특징을 추출하는 방법을 제안하며, 표정 인식과 동작 인식 두 태스크에서 SOTA를 달성하였다.

작성자
AI Research Team | 이종화
원문 논문
Encoding features robust to unseen modes of variation with attentive long short-term memory
영상을 이용해 얼굴 표정인식 작업을 수행함에 있어서 다른 생김새, 포즈, 빛의 다양성 등의 the mode of variation이 추출된 특징의 분류능력을 떨어뜨립니다. 본 논문은 mode of variation의 효과를 최소화하여 분류성능을 향상시키는 방법을 제시합니다.
소개
딥러닝을 이용해 사람의 얼굴 표정인식 작업을 할때 이를 방해할 수 있는 여러가지 정보들이 데이터에 함께 존재합니다. 예를들어 사람의 생김새나 몸 동작, 얼굴의 각도 심지어 빛의 방향 등은 표정을 인식하는데 관계 없는 정보들임에도 불구하고 정확한 표정인식을 저해하는 요소로 동작합니다[2,3]. 이러한 인지 방해요소들을 mode of variation이라고 합니다[1]. 방해요소에 영향을 받지 않는 모델을 만들기 위해 최대한 다양한 방해 요소를 함께 학습시켜서 방해 요소를 모델이 스스로 인식하도록 하는 방법을 사용하기도 합니다. 하지만 영상과 같이 입력 정보의 길이가 정해지지 않은 연속적인 데이터를 사용해서 원하는 작업을 수행하고자 한다면 거의 무한에 가까운 학습 데이터를 필요로 합니다. 결국 한정된 데이터로 학습한 모델을 최대한 활용해서 좋은 인식률을 도출해 내어야 하는데 학습시 입력되지 않은 방해 정보들인 unseen mode of variation이 존재 할 수 밖에 없습니다. 본 논문은 이 unseen mode of variation의 영향을 최소화 하기 위해 다음과 같은 방법을 제안합니다.
제안된 방법
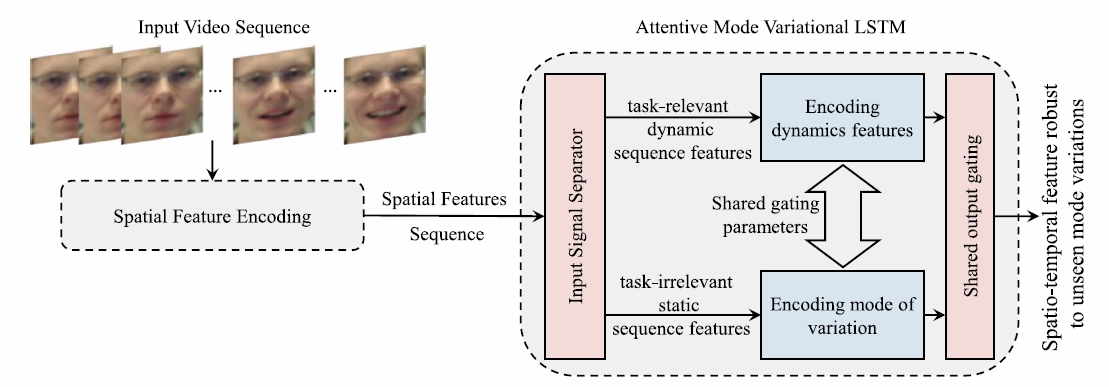
본 논문은 영상과 같은 연속입력 데이터를 task-relevant dynamic sequence features와 task-irrelevant static sequence features 두 가지로 분리합니다. task-relevant dynamic sequence features는 영상을 장면(frame)으로 나눴을 때 이전 장면과 현재 장면에 변화가 있는 부분들입니다. 이러한 변화요소는 움직임 특징(dynamic feature)를 추출해 내는데 사용됩니다. task-irrelevant static sequence features는 영상에서 변하지 않는 부분들입니다. task-irrelevant static sequence features는 인식하고자 하는 특징을 방해되는 요소인 mode of variation을 추출해 내는데 사용됩니다. 이렇게 분리해서 추출한 특징정보를 통해 Spatio-temporal feature robust to unseen mode variations를 얻을 수 있는데 이 특징정보를 사용하면 학습시 사용하지 못했던 방해되는 정보에 영향을 받지 않는 강건한 모델을 만들 수 있습니다. 자세한 내용은 다음과 같습니다.
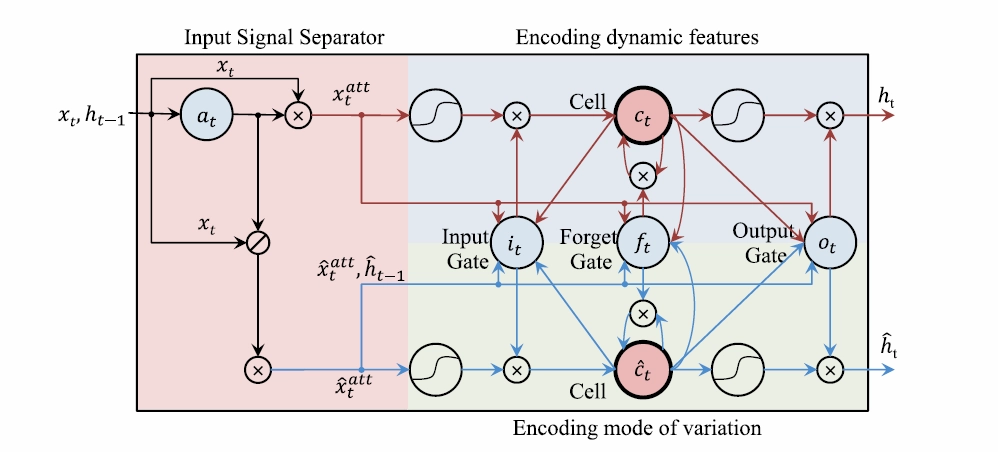
Input Signal Separator
Fig 2에 입력신호 분리기(Input Signal Separator)는 [4]에 제안된 the element-wise attetion gate의 개념에서 영감을 받아 구성되었습니다. 입력 신호 분리기는 task-relevant dynamic sequence features인 $x_{t}^{att}$와 task-irrelevant static sequence features인 $\hat x_{t}^{att}$를 분리하는 역할을 합니다. $x_{t}^{att}$와 $\hat x_{t}^{att}$를 얻기 위해서는 $a_{t}$(the element-wise dynamics attention)가 필요한데 $a_{t}$는 the element-wise dynamics attention gate를 통해 얻을 수 있습니다. gate를 이용해 $a_{t}$를 얻는 방법은 다음과 같습니다.
$a_{t} = \alpha(W_{xa}x_{t}+W_{ha}H_{t-1}+b_{a})$
$x_{t}^{att}$는 $a_{t}$에 시간 t에 따른 입력데이터를 곱해서 구할 수 있습니다. 이렇게 구해진 $x_{t}^{att}$는 입력 데이터의 움직임이 활발한 영역(dynamic features)의 특징을 강조하기 위해 사용됩니다[4].
$x_{t}^{att}=a_{t} \odot x_{t}$
다만 논문 [4]에서는 정적인 영역을 완전히 무시하는데 반해 본 논문에서는 이 정적인 영역을 인지 식별을 방해하는 mode of variation의 특징을 얻기 위해 사용합니다. task-irrelevant static sequence features은 전체 입력데이터에서 $a_{t}$을 제거한 나머지 영역을 사용합니다.
$\hat x_{t}^{att}=(1-a_{t}) \odot x_{t}$
Encoding dynamic features and mode of variation
$x_{t}^{att}$를 Input gate, forget gate에 각각 전달해서 추출된 dynamic features는 메모리 셀 $c_{t}$에 저장됩니다. $\hat x_{t}^{att}$ 또한 같은 방식으로 the mode of variation을 얻기 위해 input gate, forget gate로 전달되며 그 정보를 또 다른 메모리 셀 $\hat c_{t}$에 저장합니다. 두개의 메모리 셀의 저장된 특징 정보들은 하나의 공유된 output gate를 통과하고 이를 여러번 반복함으로써 unseen mode variation에 영향을 받지 않는 시공간 특징정보를 얻을 수 있습니다. 이 특징정보를 얻기 위해 하나의 output gate를 공유하는 이유는 두 가지가 있는데 하나는 dynamics feature와 mode of variation의 싱크를 맞추는 작업을 하는 것이고 다른 하나는 현재와 이전의 mode of varation의 특성값을 함께 가져감으로써 추출된 danamics features에 끼치는 영향을 최소화 하기 위한 것입니다.
실험
제안된 모델의 효과를 검증하기 위해 본 논문은 두 가지 작업들(task)을 수행했습니다. 얼굴 표정인식(facial expression recognition)과 사람 동작인지(human action recognition)입니다. 본 실험에는 80명을 대상으로 3개의 다른 빛을 가진 환경에서 촬영한 6개의 기본 감정(분노, 역겨움, 두려움, 행복, 슬픔, 놀람)을 가진 Oulu-CASIA 데이터셋과 실세계(real world)의 비디오 클립에서 데이터를 수집한 AFEW 데이터셋, 그리고 6개의 기본 감정에 중립감정을 더한 7개의 감정을 104명을 대상으로 13개의 웹캠으로 동시에 촬영한 KAIST Face Multi-pose Multi-illumination 데이터를 사용합니다.
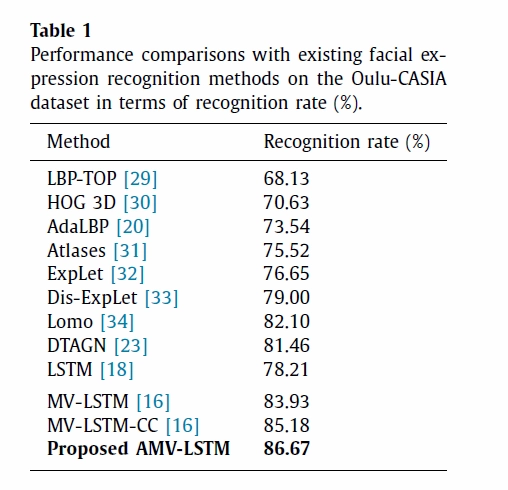
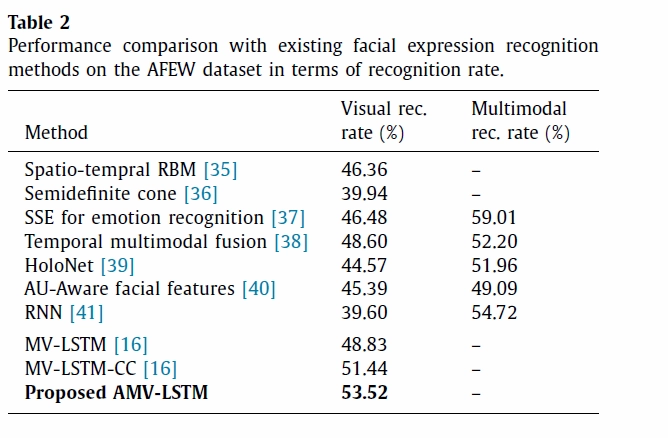
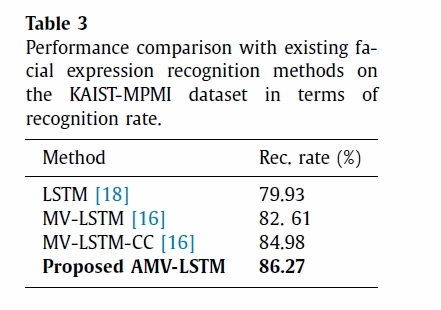
실험 1은 이전에 제안된 모델과의 성능비교를 위해 수행되었습니다. Table1, 2, 3은 각각 데이터 셋에 대한 결과를 보여줍니다. 현재 제안된 논문모델이 state-of-art(최고인지율)를 뛰어넘는 것을 확인 할 수 있습니다.
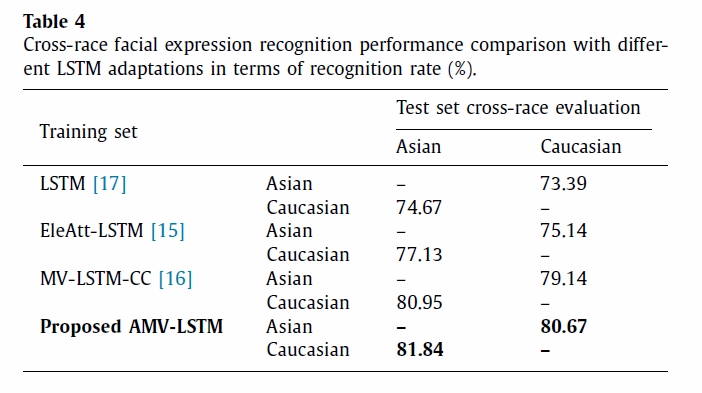
실험 2는 unseen mode of variation에 대한 robustness를 테스트 합니다. 본 실험은 외모나 생김새에 따른 모델의 인식율 저하를 확인하기 위해 Oulu-CASIA 데이터셋을 아시아인과 백인으로 나눠서 진행했습니다. Table4는 아시아인을 학습한 모델로 백인의 표정을 인지시키고 백인 그룹을 학습한 모델로 아시아인의 표정을 인지했을 때의 결과입니다. 이를 통해 본 논문에서 제안하는 모델은 대상의 외모에 변화에 더욱 강건한 특징을 추출해 내는 것을 알 수 있습니다.
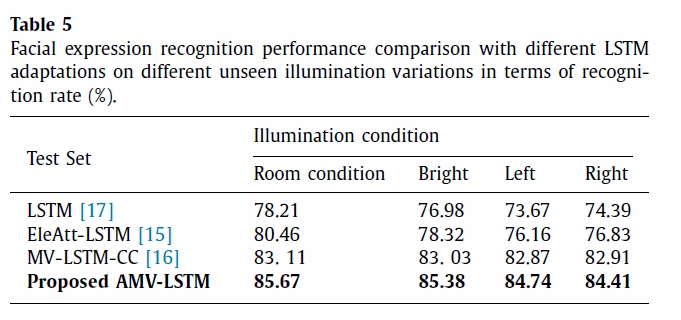
빛에 변화에 대한 인식률을 확인하기 위해서 KAIST Face MPMI 데이터 셋을 이용해서 다음 실험도 진행했습니다. Room condition의 빛을 가진 학습 데이터를 가지고 방이 환할 때, 왼쪽에서 빛이 비출때, 오른쪽에서 빛을 비출때 사람의 표정을 각각 인지하도록 하였습니다. 제안된 모델은 빛의 방향성과 강함에 관계없이 뛰어난 인지율을 보여줍니다.
결론
본 논문에서는 unseen mode of variation에 영향을 최소화 하는 특징을 추출하기 위한 모델을 설계하는 방법을 제안합니다. 이 제안의 핵심인 attentive mode variational LSTM은 attention 컨셉을 사용해 입력정보를 task-relevant dynamic sequence features와 task-irrelevant static sequence features로 구분합니다. 위 각각의 특징들은 dynamics 특징정보와 mode of varation을 추출하기 위해 사용되고 추출된 정보들은 하나의 공유된 output gate를 통해서 Spatio-temporal feautre robust to unseen mode variations로 변환됩니다. 표정 인식(facial expression recognition)과 동작인식(human action recognition) 두개의 작업(task)로 수행된 실험들은 이 특징의 효과를 입증하며 각각의 영역에서 state of the art(SOTA)를 갱신했습니다.
참고문헌
[1] Wang et al., "Disentangling the Modes of Variation in Unlabelled Data," IEEE TPAMI 2017.
[2] Shahroudy et al., "NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis," CVPR 2016.
[3] Zhang et al., "View Adaptive Recurrent Neural Networks for High Performance Human Action Recognition from Skeleton Data," ICCV 2017.
[4] Zhang et al., "Adding Attentiveness to the Neurons in Recurrent Neural Networks," ECCV 2018.
[16] Baddar et al., "Mode Variational LSTM Robust to Unseen Modes of Variation: Application to Facial Expression Recognition," AAAI 2019.

