딥 컨볼루션 신경망의 일반화 능력을 활용한 컬러 안저 사진의 분류기 개선
본 논문은 Classifier의 confidence 기반 노이즈 레이블 필터링과 pseudo-labeling을 결합한 SSL 방식을 제안하며, 노이즈 데이터와 희귀 양성 사례 탐지 모두에서 우수한 성능을 보였고 최종적으로 off-site validation set에서 AUROC 0.9993을 달성하였다.

작성자
AI Research Team | 김재영
원문 논문
Author Contributions
Author Contributions: Conceptualization, J.S., J.K. and S.T.K.;Formal Analysis, J.S. and J.K.; Methodology, J.S., J.K., S.T.K. and K.-H.J.; Writing—Original draft, J.S., J.K. and S.T.K.; Writing—Review & Editing, J.S. and K.-H.J.; Supervision, K.-H.J. All authors have read and agreed to the published version of the manuscript.
Intro
딥러닝을 이용하여 문제를 해결하고자 할 때, 인적자원 및 비용절감을 위해 "크라우드소싱"과 같은 방식을 이용해 데이터를 구축하곤 하지만 딥러닝 모델의 성능은 데이터의 품질과 양에 의존적인 경우가 많습니다. 하지만 비전문가들에의해 구축된 데이터나 이와 같은 real-world dataset은 여러가지 human-error들에 의해 부정확할 수 있으며 이는 모델의 일반화 성능을 저하시키는 요인이 될 수 있습니다. 또한 많은 경우에 minor class에 대한 labeled 데이터를 확보하는 것은 현실적으로 불가능하거나 많은 시간과 노력이 필요하기 때문에 "long-tail distribution" 으로 인한 성능저하도 고려해야 합니다. 따라서 현업에서 딥러닝모델을 설계하고 학습할 때에는 다양한 상황에 대한 고민이 필요하며 보다 강건한 모델을 만드는 것이 중요합니다.
제가 참여한 팀은 앞서 말한 문제들을 해결하기 위한 기술을 연구하여 의료 Top conference인 MICCAI 에서 진행된 pathological myopia classification challenge (PALM) 대회에 참가하였고, 해당 부분에서 1등을 하는 성과를 보였습니다. 본 포스팅에선 대회에서 다루었던 다양한 practical 테크닉을 소개하고 보다 자세한 설명은 논문 에서 확인하실 수 있습니다.
본 논문에서 사용된 데이터가 제네시스랩에서 다루는 모달리티와는 차이가 있어보이지만, 이 기술은 제네시스랩의 딥러닝 모델 뿐만 아니라 다양한 deep learning-based application 에도 적용할 수 있기 때문에 소개 드리고자 합니다.
Dataset
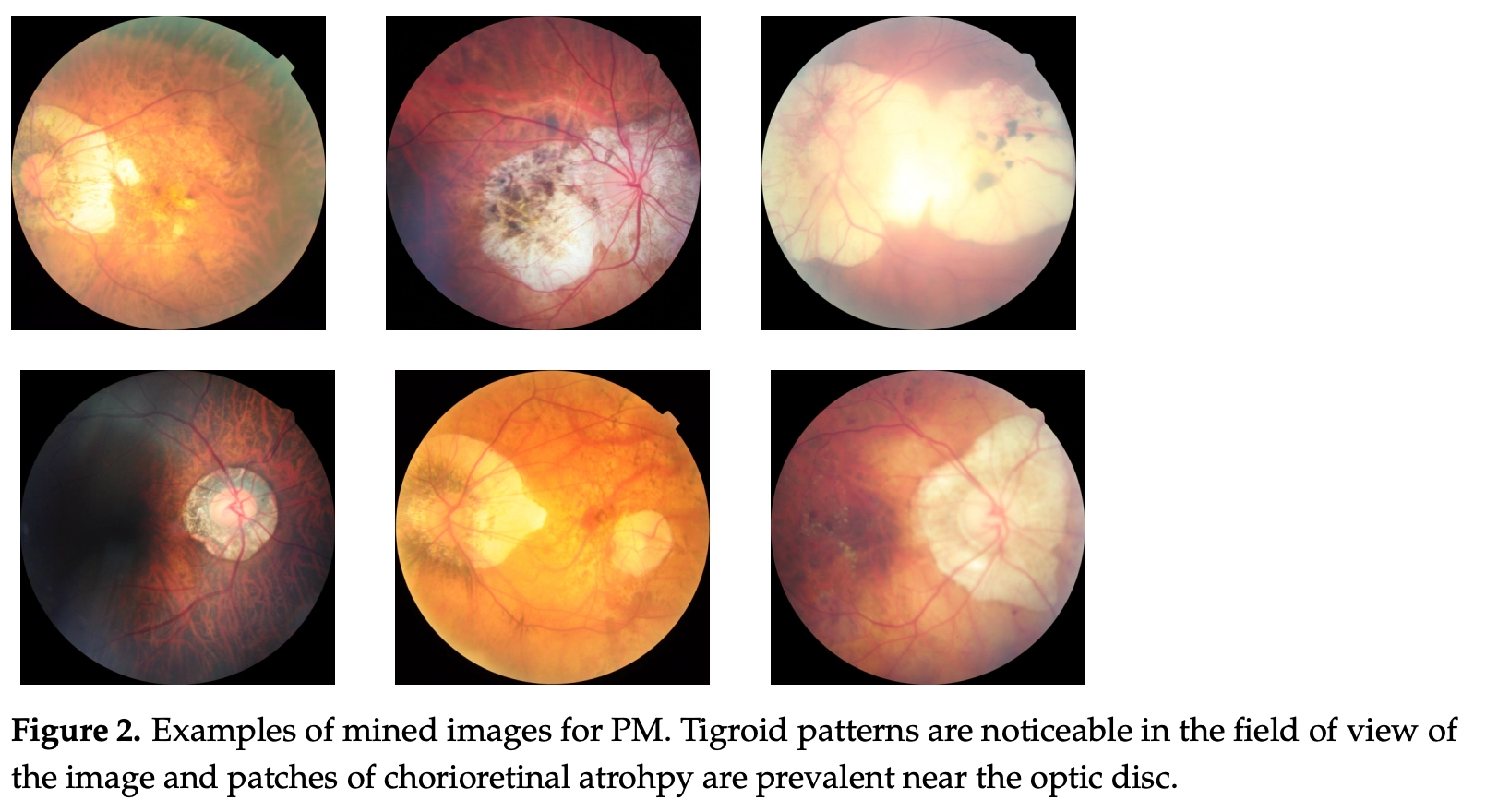
Pathological myopia (PM) 을 예측하는 task 를 풀기위해 안저영상을 이용했고, 위 이미지 는 PM 이 발생한 안저영상의 예시입니다. PM의 경우 tigroid pattern을 보인다는 특징을 가진다는 점 이외에도 retinal detachment 유무와 같이 다른 임상적 근거에 의해서도 PM으로 판단할 수 있습니다. Pathological myopia (PM)은 통상적으로 0.9–3.1% 의 아시아인들에게 1.2% 의 Australian에게 발병하기 때문에 학습 데이터셋 또한 positive case 비율이 낮았으며 400개의 labeled dataset으로 구성되어 있습니다.
Method
참가한 대회에서 딥러닝 모델의 일반화 성능을 끌어올리기 위해 사용한 방식은 크게 2가지입니다.
첫째, 준지도학습을 이용하여 unlabeled samples를 추가적인 학습에 이용하는 방법
둘째, noisy dataset의 영향을 줄이기 위해 noise positive data 을 탐지하는 filtration networks 를 설계하여 filtration networks로부터 탐지된 노이즈 데이터를 타겟 task 학습에 제외시키는 방식입니다.
Leveraging the Generalization Ability of CNNs for pseudo-labeling
학습데이터가 충분하지 않을 때 사용할 수 있는 방법중에 하나는 unlabeled data를 이용한 semi-supervised learning (SSL) 입니다. SSL의 방식 중에서 pseudo-labeling은 많은 연구들에서 효용성이 입증된 방식입니다. 하지만 기존 pseudo-labeling의 방식들은 class간의 분포가 balanced한 상황을 주로 다루었지만 "long-tail distribution" dataset에서 학습된 모델에 pseudo-labeling을 적용할 경우 모델은 sub-par performance를 가질 수 있으며 scarce dataset으로 학습된 모델의 pseudo-label을 신뢰하긴 어렵습니다. 따라서 우리는 좀 더 정확한 pseudo-label을 획득하기 위해 도메인에 대한 사전지식과 데이터 불균형 및 크기를 고려하여 다음과 같은 가설을 세웠습니다.
- Pathological myopia (PM)은 통상적으로 0.9–3.1% 의 비율로 발병하기 때문에 PM데이터셋이 아니라면 public fundus images에서의 PM 비율이 Normal case를 압도하진 않을 것이다.
- Deep Neural Networks (DNNs)은 노이즈데이터셋으로 학습될지라도 학습초기에 데이터들의 general feature를 먼저 학습하고 학습이 진행됨에 따라 memorization이 진행된다.
저희 팀은 이 가설들을 이용하여 수집한 unlabeled public dataset 의 레이블을 사전에 모두 "정상"으로 labeling한 뒤 labeled dataset과 함께 학습을 진행했습니다. 이 때 public dataset의 레이블을 모두 정상으로 가정했기 때문에 노이즈가 포함되지만 학습초기 모델의 예측값을 이용해 public dataset에 대한 pseudo-labeling을 생성하는 방식을 사용했습니다. 그 후 public dataset을 대회기간의 학습 데이터로, 대회에서 제공한 학습데이터셋을 평가데이터셋으로 두고 재학습하여 모델을 구축했습니다. 추가적인 데이터 확보를 위해 91,509장의 unlabeled public images을 수집했으며 Kaggle [1], Messidor [2], IDRiD [3], REFUGE [4], and RIGA [5] 데이터셋을 사용했습니다.
Filtering Suspicious Data
저희 팀은noisy dataset의 영향을 줄이기 위해 noise positive data 을 탐지하는 filtration networks 를 설계하여 filtration networks $b$ 로부터 탐지된 노이즈 데이터를 PM classification model $f \rightarrow \hat{p}\in\Delta(\mathbb{y})$학습에 제외시키는 방식을 사용했습니다.
$b$ 는 uncorrupted validation dataset $D_{val}$ 과 $f$의 posterior distribution을 이용하여 noise positive data 을 탐지합니다. Filtration networks $b$ 의 학습은 $f$의 epoch마다 진행이 되며 $D_{val}$ 에 대한 $f$의 posterior distribution $\hat{p}$을 인풋으로 받아 true label $y_{val}$과의 오차를 줄이는 방향으로 진행됩니다. 따라서 Well-trained Filtration networks $b^*$는 clean positive data에 보다 높은 confidence를 가지며 반대로 suspiciously negative data에 대해서는 낮은 confidence를 가질 수 있습니다.
$b^*$는 $f$의 epoch마다 학습되기 때문에 training time의 효율성을 위해 logistic regression model ($b(\hat{p})=w^T\hat{p}$)을 사용합니다. 결과적으로 train samples $D_{train}$ 에 대해 $b^*$가 $\tau$ 이상의 confidence를 가지는 노이즈 데이터로 판단한다면 해당 데이터는 $f$의 학습에 기여하지 않습니다:
$\theta_f = \theta_f - \eta \nabla L(\theta_f;x,y)\mathbf{1}\{b^*(\hat{p})>\tau\}$
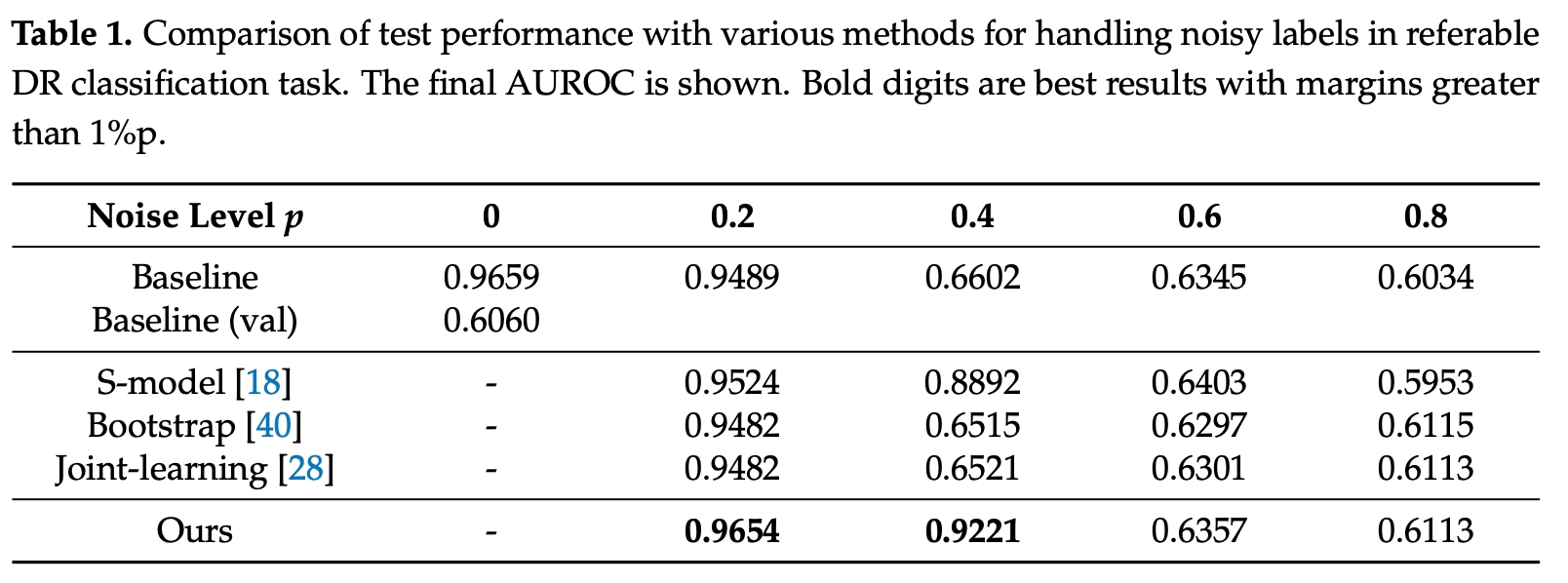
우리는 filtration network의 타당성을 확인하기 위해 Kaggle 2015 dataset with 35,126 images (17,563 eyes) for training and 53,576 images (26,788 eyes) 으로 기존 state-of-the-art 방식들과의 quantitative result를 비교해 보았고, 제안된 방식은 p < 0.5 에서 highest accuracy의 결과를 보였습니다 (Table 1).
Conclusion
본 포스팅에서 Classifier의 confidence를 이용한 filtering noisy labels 방법과 publicly-available unlabeled data를 이용한 SSL 방식을 소개했습니다. 우리가 제안한 noisy label filtration method는 노이즈가 첨가된 데이터셋에서 기존의 방식보다 높은 성능을 보였고 DNNs의 generalize ability 를 이용한 pseudo-labeling 방식은 rare positive cases를 탐지하는데 효과적이었으며 original small training set에서는 학습하기 어려운 unfamiliar patterns의 학습을 가능하게 함으로써 높은 성능을 얻을 수 있었습니다. 최종적으로 우리는 대회에서 off-site validation set에 대해 0.9993의 AUROC 성능을 보이면서 대회를 마무리 할 수 있었습니다.
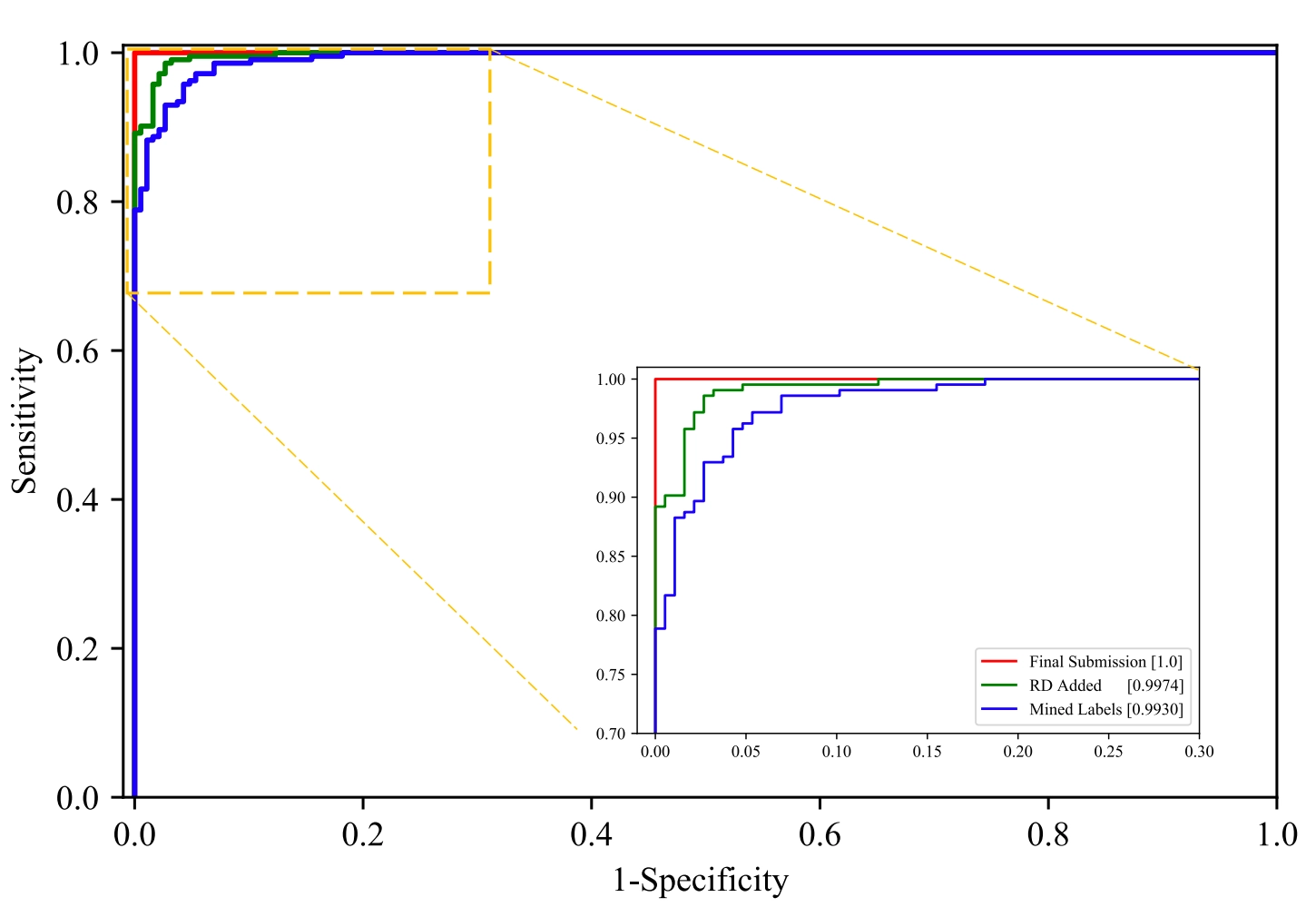
우리는 대회를 통해 제안된 방식을 의료데이터에 적용했지만, a large volume of labeled data를 요구하는 real-world settings에 다양하게 적용될 수 있을 것으로 기대합니다.
참고문헌
[1] Kaggle, "Diabetic Retinopathy Detection Competition Report," Kaggle 2015.
[2] Decencière et al., "Feedback on a Publicly Distributed Database: The Messidor Database," Image Anal. Stereol. 2014.
[3] Porwal et al., "Indian Diabetic Retinopathy Image Dataset (IDRiD): A Database for Diabetic Retinopathy Screening Research," Data 2018.
[4] "Retinal Fundus Glaucoma Challenge," REFUGE Grand Challenge 2019.
[5] Almazroa et al., "Retinal Fundus Images for Glaucoma Analysis: The RIGA Dataset," SPIE Medical Imaging 2018.

