적대적 학습 기반의 경량·고효율 얼굴 랜드마크 검출: Face Geometric Map 생성 네트워크
논문은 얼굴의 기하학적 정보를 활용한 적대적 학습이 FLD 성능을 향상시킨다는 것을 보여주며, 테스트 시 인코더만으로 랜드마크를 추출할 수 있는 간단하고 효과적인 구조를 제안한다는 점에서 의의가 있다.

작성자
AI Research Team | 최석규
원문 논문
Facial Landmark는 얼굴을 구성하는 핵심 요소 (눈, 눈썹, 코, 입, 턱선)를 나타내는 특징점들입니다. 특징점들은 일반적으로 68개의 점으로 얼굴의 특징들을 표현하며 이미지 안에서 얼굴을 찾기 위해서 사용됩니다. 따라서 정교한 얼굴을 찾기 위해서 얼굴 랜드마크 검출(Facial Landmark Detection)은 매우 중요합니다. 알고리즘을 통해 검출된 얼굴 랜드마크는 얼굴 탐지 뿐만 아니라 머리 자세 추정, 감정 인식 등 컴퓨터 비전의 여러 분야에 사용될 수 있습니다.
얼굴 랜드마크(Facial Landmark)
얼굴 랜드마크 검출은 얼굴의 중요 요소들의 위치를 찾는 과제(task)로 컴퓨터 비전 과제에 필수적인 정보들을 제공합니다. 대표적인 방법론으로는 초기에 검출된 얼굴 요소들을 실제 얼굴 위치로 보내기 위해 움직일 방향을 예측하는 최적화 기반 방법과 학습된 파라미터를 이용하여 이미지에서의 얼굴 요소 위치를 직접적으로 예측하는 회귀 기반 방법이 있습니다. 물론 최근에는 다른 과제들과 마찬가지로 딥러닝 기반 방법이 좋은 성능을 보이고 있습니다. 딥러닝 기반 연구가 활발히 일어남에 따라 얼굴 탐지와 머리 자세 추정 등의 과제들을 한 번에 풀고자 하는 멀티태스크 학습 방법과 같은 다양한 방법론들이 연구되었습니다. 이러한 얼굴 랜드마크 검출 기반의 연구들은 모바일이나 웹과 같은 어플리케이션에 적용되어야 하기 때문에 모델이 간단하면서 정확한 성능을 낼 수 있어야 합니다. 하지만 간단한 CNN 구조를 이용할 시 얼굴 윤곽이 어긋난 이미지인 경우 매우 좋지 않은 성능을 보입니다. 이를 해결하기 위해 얼굴 내부 요소와 윤곽을 예측하는 두 개의 서브 네트워크를 이용한 연구가 이 문제를 완화하였지만 해결했다고 보기는 힘듭니다.

소개(Introduction)
얼굴 랜드마크 검출은 얼굴의 중요 요소들의 위치를 찾는 과제(task)로 컴퓨터 비전 과제에 필수적인 정보들을 제공합니다. 대표적인 방법론으로는 초기에 검출된 얼굴 요소들을 실제 얼굴 위치로 보내기 위해 움직일 방향을 예측하는 최적화 기반 방법과 학습된 파라미터를 이용하여 이미지에서의 얼굴 요소 위치를 직접적으로 예측하는 회귀 기반 방법이 있습니다. 물론 최근에는 다른 과제들과 마찬가지로 딥러닝 기반 방법이 좋은 성능을 보이고 있습니다. 딥러닝 기반 연구가 활발히 일어남에 따라 얼굴 탐지와 머리 자세 추정 등의 과제들을 한 번에 풀고자 하는 멀티태스크 학습 방법과 같은 다양한 방법론들이 연구되었습니다. 이러한 얼굴 랜드마크 검출 기반의 연구들은 모바일이나 웹과 같은 어플리케이션에 적용되어야 하기 때문에 모델이 간단하면서 정확한 성능을 낼 수 있어야 합니다. 하지만 간단한 CNN 구조를 이용할 시 얼굴 윤곽이 어긋난 이미지인 경우 매우 좋지 않은 성능을 보입니다. 이를 해결하기 위해 얼굴 내부 요소와 윤곽을 예측하는 두 개의 서브 네트워크를 이용한 연구가 이 문제를 완화하였지만 해결했다고 보기는 힘듭니다.
본 논문에서는 생성 모델과 판별 모델을 적대적으로 학습하는 GAN을 기반으로 한 Geometric Prior-Generative Adversarial Network를 제안합니다. 제안 모델은 기존에 L1이나 L2 loss를 이용하여 실제 Facial Landmark와 예측된 Facial Landmark 사이의 차이를 학습하는 방식과 달리 적대적이고 얼굴의 기하학적 특징을 고려한 loss를 이용합니다. 본 논문에서 얼굴 이미지에서 얼굴 랜드마크 좌표를 예측하도록 학습된 인코더(Encoder)의 출력 값을 받아 얼굴 윤곽의 기하학적 맵과 얼굴 내부의 기하학적 맵을 예측하도록 생성모델(Generator)을 학습합니다. 또한 판별 모델(Discriminator)은 실제 얼굴 랜드마크와 생성 모델이 만든 얼굴 랜드마크를 구별하도록 학습하도록 모델을 고안하였습니다.
얼굴 기하학 생성적 적대 신경망
모델 개요(Model Overview)
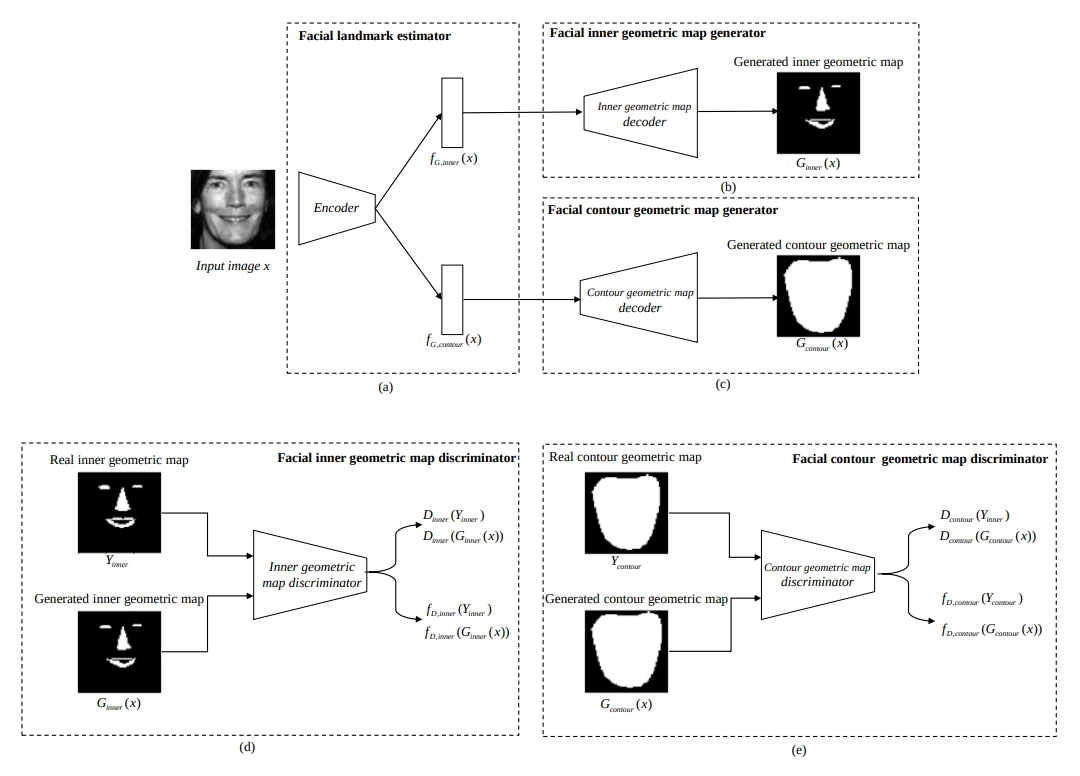
Face Geometric Map Generator 학습
생성기는 입력 이미지로부터 얼굴 내부 및 윤곽 랜드마크를 예측하는 인코더 1개와, 인코더 출력값으로부터 기하 지도를 생성하는 디코더 2개로 구성됩니다. 기하학적 얼굴 특징은 잘린 얼굴(cropped)이나 각도가 있는 얼굴(angled face) 등 다양한 노이즈가 포함된 이미지에서 랜드마크를 정확히 예측하는 데 중요합니다.
기존의 L1/L2 방법은 정답과 예측값의 차이만 고려하기 때문에 이러한 특징을 충분히 반영하지 못합니다. 반면 본 논문에서는 생성기 인코더가 내부/윤곽 랜드마크를 각각 예측하고, 생성기 디코더가 이를 활용해 기하 지도를 생성합니다.
생성기 학습 시에는 adversarial loss뿐 아니라, 판별기의 예측 손실도 함께 고려하지만 판별기의 파라미터는 고정됩니다.
판별기(Discriminator) 학습
각각의 판별 모델은 입력으로 받은 기하하적 맵이 진짜인지 생성된 것인지 판별하고 랜드마크의 좌표들을 예측하도록 학습합니다. 판별 함수의 손실 함수 중에는 생성 모델 학습 중에 계산되어지는 손실 함수도 존재합니다. 생성 모델 학습 시에는 판별 함수의 파라미터가 업데이트 되지 않기 때문에 loss를 최소화하기 위해서 생성 모델이 기하하적 맵을 생성할 때 더 진짜 같이 생성하도록 학습됩니다. 이와 유사하게 판별 모델 학습 시에는 생성 모델의 파라미터가 업데이트되지 않도록 합니다.
실험 결과(Experiment Result)
| Name | Train | Test | Argumentation Data |
|---|---|---|---|
| HELEN DATASET | 2,000 | 330 | 24,000 |
| 300-W DATASET | 3,148 | 689 | 40,082 |
실험에 사용된 데이터 셋은 HELEN과 300-W입니다. HELEN은 두 개의 annotation 정보가 함께 있는데 하나는 194개의 랜드마크이고 나머지는 68개 랜드마크입니다. 300-W는 4개의 subset(AFW, LFPW, HELEN, IBUG)으로 구성되어 있으며 학습 데이터는 3,148개(AFW : 377+HELEN : 2,000+LFPW : 811), 테스트 데이터는 689개(LFPW : 224+HELEN : 300+IBUG : 135)로 구성되어 있습니다. 또한 데이터 증강을 위해 translation, rotation, magnification을 사용하였습니다.
성능 비교 실험(Experiments for Performance Comparison)
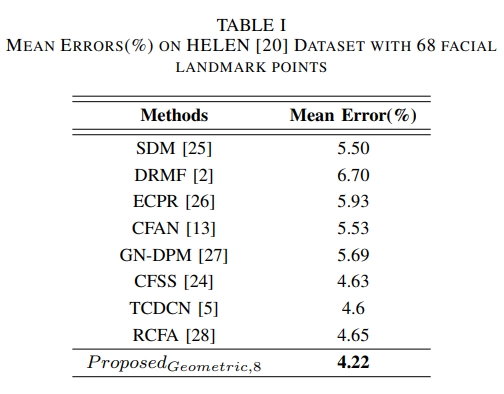
위의 표를 보시면 기존의 연구들보다 성능이 좋으며 MAFL Database로 Pretraining한 TCDCN과 face alignment를 위해 RNN을 사용한 RCFA보다 성능이 좋은 것을 확인 하실 수 있습니다.
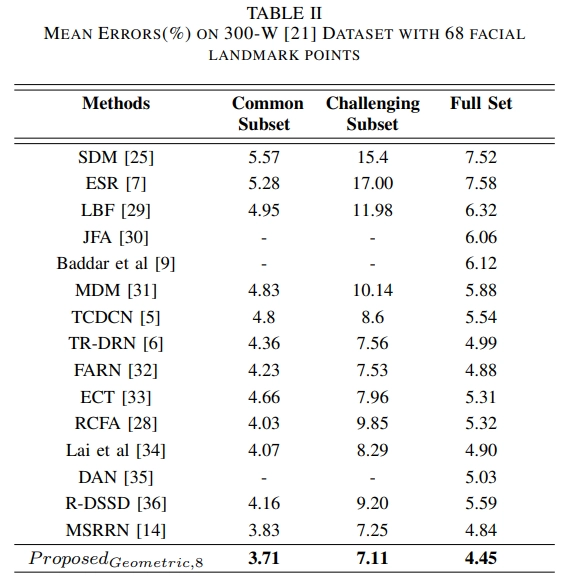
위의 표를 통해 랜드마크를 제대로 예측하기 어려운 이미지들이 포함된 300-W에서도 본 논문에서 제안한 모델이 가장 좋은 성능을 보여 다른 모델들보다 강건하다고 볼 수 있습니다.
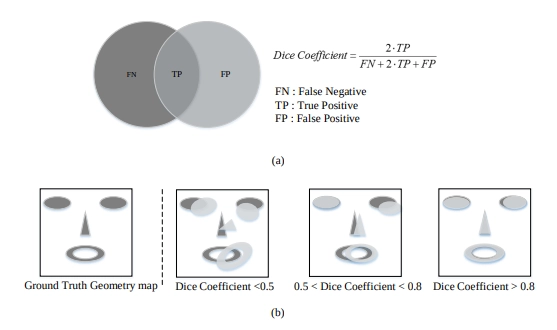
윤곽(Contour) 지도 유용성 실험(Experiment Results for Usefulness of Contour Map)
본 논문에서는 실험을 통해 얼굴 윤곽의 기하학적 맵 활용에 대한 효과를 측정하였습니다.
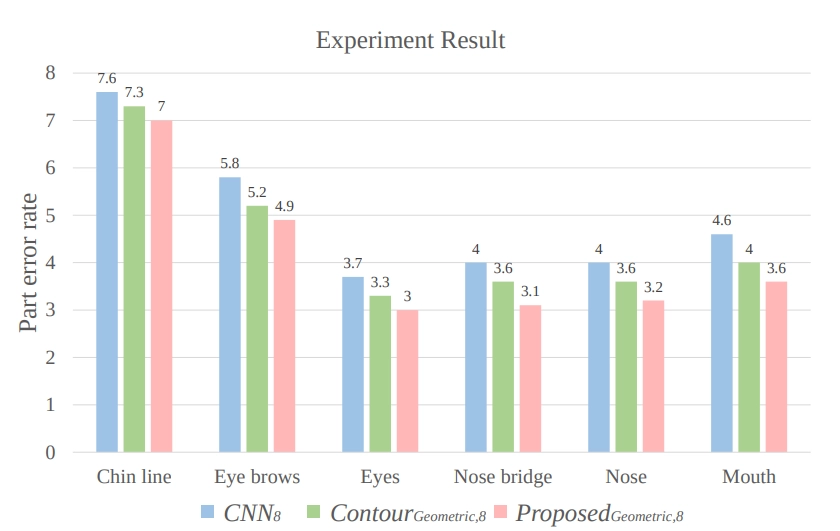
위 그래프는 세가지 모델을 통한 실험으로 각 모델의 구조는 같지만 학습 방식이 다릅니다. CNN8은 L1을 이용하여 최적화한 모델이고, ContourGeometric8은 Facial Inner를 제외하고 학습한 모델입니다. 위 실험 결과를 보면 일반적인 L1 loss를 이용한 방식보다는 얼굴 윤곽을 이용한 방식이 성능이 더 좋으며 얼굴의 내부 정보까지 활용했을 때 성능 향상을 보이는 것을 알 수 있습니다.
결론(Conclusion)
본 연구를 통해 FLD 과제에서 얼굴의 기하학적 정보를 이용하여 적대적으로 학습하는 것이 기존 연구들에 좋은 성능을 보인다는 것을 확인할 수 있었습니다. 또한 정확한 얼굴 윤곽이 얼굴 내부 랜드마크의 위치를 더 잘 찾게 해준다는 점을 알 수 있었습니다. 테스트 단계에서는 인코더만 사용하여 랜드마크를 뽑아낼 수 있기 때문에 여러 어플케이션에 잘 적용할 수 있는 간단하고 효과적인 FLD 네트워크를 만들고자 하는 목표에 달성했다고 볼 수 있습니다.
참고문헌
[2] Asthana et al., "Robust Discriminative Response Map Fitting with Constrained Local Models," CVPR 2013.
[5] Zhang et al., "Learning Deep Representation for Face Alignment with Auxiliary Attributes," IEEE TPAMI 2016.
[6] Lv et al., "A Deep Regression Architecture with Two-Stage Re-initialization for High Performance Facial Landmark Detection," CVPR 2017.
[7] Cao et al., "Face Alignment by Explicit Shape Regression," IJCV 2014.
[13] Zhang et al., "Coarse-to-Fine Auto-Encoder Networks (CFAN) for Real-Time Face Alignment," ECCV 2014.
[14] Wang et al., "Multiscale Recurrent Regression Networks for Face Alignment," Applied Informatics 2017.
[24] Zhu et al., "Face Alignment by Coarse-to-Fine Shape Searching," CVPR 2015.
[25] Xiong et al., "Supervised Descent Method and Its Applications to Face Alignment," CVPR 2013.
[26] Burgos-Artizzu et al., "Robust Face Landmark Estimation under Occlusion," ICCV 2013.
[27] Tzimiropoulos et al., "Gauss-Newton Deformable Part Models for Face Alignment In-the-Wild," CVPR 2014.
[28] Wang et al., "Recurrent Convolutional Face Alignment," ACCV 2016.
[29] Ren et al., "Face Alignment at 3000 FPS via Regressing Local Binary Features," CVPR 2014.
[30] Xu et al., "Joint Head Pose Estimation and Face Alignment Framework Using Global and Local CNN Features," IEEE FG 2017.
[31] Trigeorgis et al., "Mnemonic Descent Method: A Recurrent Process Applied for End-to-End Face Alignment," CVPR 2016.
[32] Hou et al., "Face Alignment Recurrent Network," Pattern Recognition 2018.
[33] Zhang et al., "Combining Data-Driven and Model-Driven Methods for Robust Facial Landmark Detection," IEEE TIFS 2018.
[34] Lai et al., "Deep Recurrent Regression for Facial Landmark Detection," IEEE TCSVT 2016.
[35] Kowalski et al., "Deep Alignment Network: A Convolutional Neural Network for Robust Face Alignment," CVPRW 2017.
[36] Liu et al., "Learning Deep Sharable and Structural Detectors for Face Alignment," IEEE TIP 2017.

