Encoding features robust to unseen modes of variation with attentive long short-term memory
This paper proposes an attentive mode variational LSTM that disentangles task-relevant and task-irrelevant features, achieving state-of-the-art on facial expression and action recognition.

작성자
AI Research Team | Jong Hwa Lee
Original Paper
Encoding features robust to unseen modes of variation with attentive long short-term memory
When classifying the dynamics in video sequences of facial expressions, what could significantly hurt the quality of encoded features—some of which are irrelevant to the facial expression recognition task—is called mode of variation: subject appearance variations, viewpoint variations, illumination or even body posture variations. This paper presents a method to improve the classification performance by minimizing the impact of mode of variation.
Introduction
When using deep learning to recognize a person's facial expression, there is a lot of information in the data that can interfere with the task. For example, appearance variations, viewpoint variations, body posture variations, or even illumination acts as a hindrance to accurate recognition of facial expressions. These disturbances are called mode of variation. In order to overcome these barriers, a method has also been used to expose its model to as many variations as possible so that the model can recognize variations on its own. However, when it comes to using videos to get encoded features, obtaining training datasets that could contain all possible modes of variation is out of the question. In other words, unseen mode of variation should always exist and this paper proposes a method that can minimize it.
Proposed method
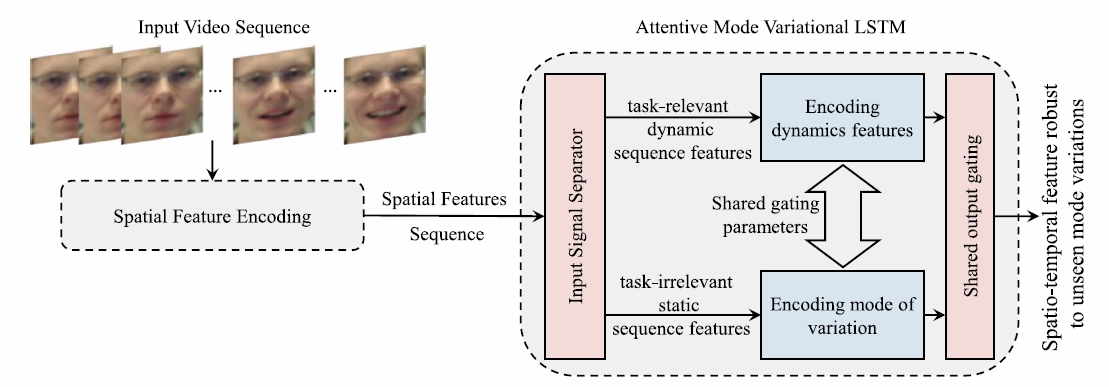
This paper divides continuous input data such as video sequences into two types: task-relevant dynamic sequence features and task-irrelevant static sequence features. Task-relevant dynamic sequence features to encode dynamic features mean the parts where there is a change in a previous scene and a current one when the video is divided into frames. On the other hand, task-irrelevant static sequence features are unchanging parts of the image. The task-irrelevant static sequence features are to encode mode of variation, a barrier to given recognition tasks. This separately encoded feature information yields the Spatio-temporal feature robust to unseen mode variations, not to be affected by variations unseen during the training. More details are as follows:
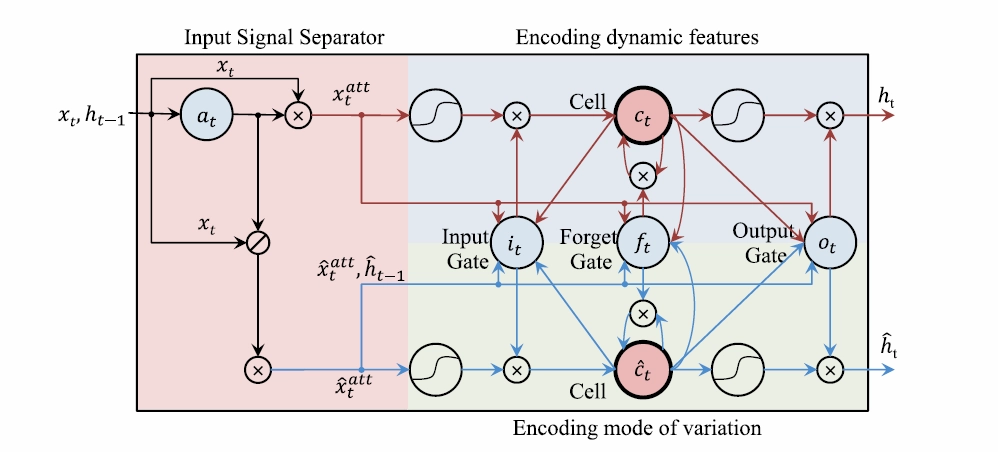
Input Signal Separator
The input signal separator in Fig 2, inspired by the concept of the element-wise attention gate proposed in [4], separates input sequence features into two parts: task-relevant dynamic sequence features $x_{t}^{att}$ and task-irrelevant static sequence features $\hat x_{t}^{att}. a_{t}$ (the element-wise dynamics attention) is necessary to get $x_{t}^{att}$ and $\hat x_{t}^{att}$, and the element-wise dynamics attention gate helps get $a_{t}$ as shown in the equation below.
$a_{t} = \alpha(W_{xa}x_{t}+W_{ha}H_{t-1}+b_{a})$
$x_{t}^{att}$ can be obtained by multiplying $a_{t}$ by time (t). Then, $x_{t}^{att}$ is used to emphasize dynamic features in the input sequence [4].
$x_{t}^{att}=a_{t} \odot x_{t}$
Please note that in the paper [4], static sequences are completely ignored, whereas in this paper they are used to encode mode of variations that prevents the recognition and identification of features. Task-irrelevant static sequence features use the remaining area where $a_{t}$ has been removed from the entire input data.
$\hat x_{t}^{att}=(1-a_{t}) \odot x_{t}$
Encoding dynamic features and mode of variation
Dynamic features that are encoded by passing $x_{t}^{att}$ through the input gate and the target gate are stored in memory cell $c_{t}$. $\hat x_{t}^{att}$ also goes through the input gate and the forget gate to obtain the mode of variation which is stored in another memory cell $\hat c_{t}$. The stored feature data in the two memory cells then pass through one shared output gate and, by repeating the process several times, spatio-temporal feature information robust to unseen mode variations is obtained. Notice that only one output gate is used. This is primarily the case for two reasons: (1) to synchronize dynamics features and mode of variation and (2) to minimize the effect of the mode of variation on the dynamics features encoded by bringing the current and previous mode of variation together.
Experiment
To validate the effectiveness of the proposed model, two tasks have been performed: facial expression recognition task and human action recognition task. For facial expression recognition, three datasets were used. Oulu-CASIA facial expression dataset in which sequences of the six basic facial expressions (i.e., angry, disgust, fear, happy, sad, and surprise) were collected from 80 subjects under three different illumination conditions; AFEW dataset to emulate real-world conditions collected from movies; and the KAIST face multi-pose multi-illumination (KAIST Face MPMI) dataset that, via thirteen web cameras, simultaneously recorded each expression sequence of the seven expressions (the six basic expressions and a neutral expression sequence) from 104 subjects.
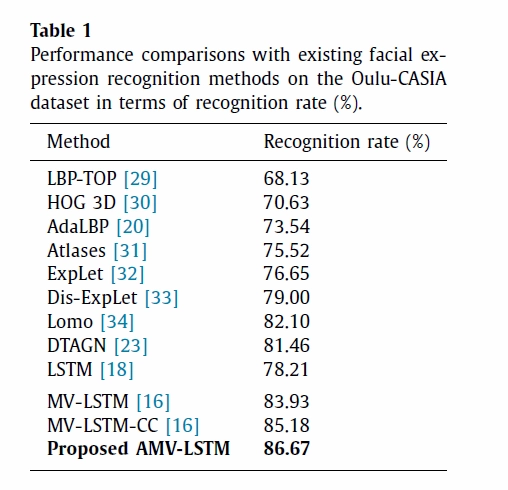
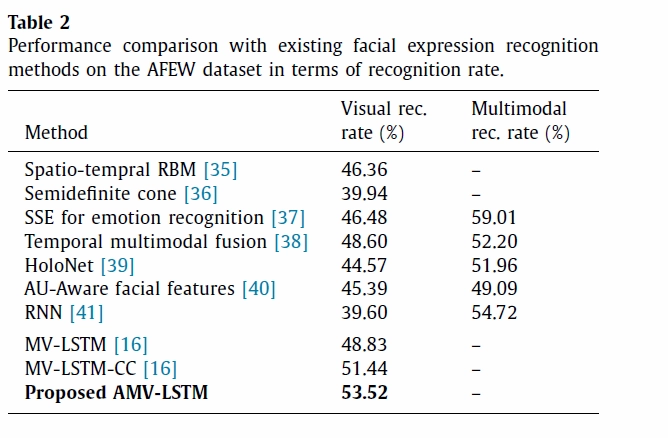
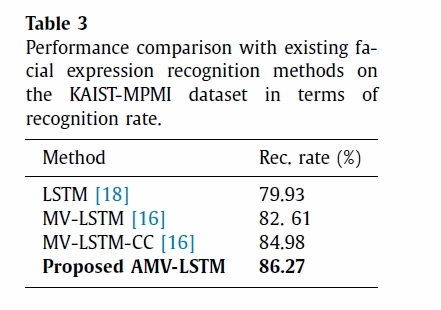
The object of experiment 1 was to compare performance with previously proposed models. Table 1, 2, and 3 show the results for each data set, and the model this thesis proposes outperforms state-of-the-art methods on both tasks.
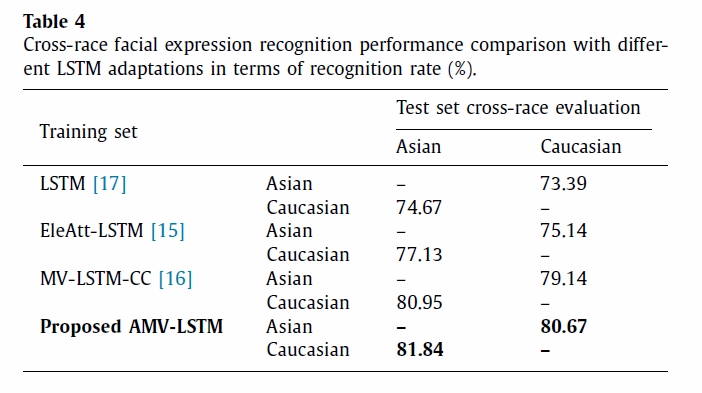
Experiment 2 evaluates the robustness of the proposed method to encode features robust to unseen modes of variation. In the experiment, Oulu-CASIA dataset is divided into Asian and Finnish (Caucasian) subjects to see if appearance reduces facial expression recognition rates. Table 4 is the result of two tests: when we first trained the models using the Asian subjects and validate the performance on the Caucasian subjects and vice versa. This result shows that the proposed model in this paper encodes features that are more robust to subject appearance variations.
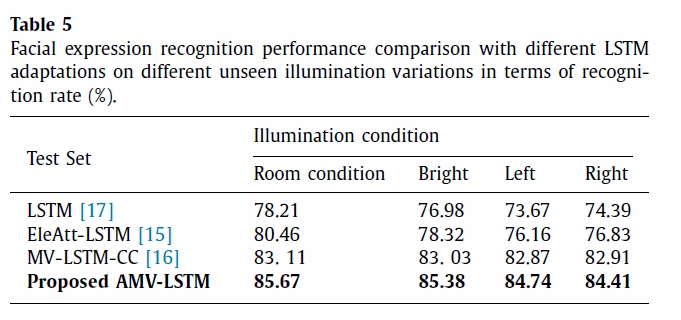
Another experiment was carried out with the KAIST Face MPMI dataset to assess the robustness of the proposed model towards unseen illumination variations. To that end, the models are trained using only the sequences captured under the room illumination conditions and tested on all illumination variations (i.e., sequences with room illumination condition, bright illumination condition, left illumination condition and right illumination condition). The proposed model shows excellent recognition rates regardless of the direction and strength of illumination.
Conclusion
In this paper, we proposed a method to encode features robust to unseen modes of variation. Attentive mode variable LSTM, the core of this proposal, uses the concept of attention to separate the input sequence into task-relevant dynamic sequence features and task-irrelevant static sequence features. Each of the features is used to encode dynamics features and mode of variation, and the encoded information is converted into a Spatio-temporal feature robust to unseen mode variations through a single shared output gate. Experiments conducted on two tasks, facial expression recognition and human action recognition, demonstrated the effectiveness of the proposed method and proved to be superior to the state of the art (SOTA) in each task.
References
[1] Wang et al., "Disentangling the Modes of Variation in Unlabelled Data," IEEE TPAMI 2017.
[2] Shahroudy et al., "NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis," CVPR 2016.
[3] Zhang et al., "View Adaptive Recurrent Neural Networks for High Performance Human Action Recognition from Skeleton Data," ICCV 2017.
[4] Zhang et al., "Adding Attentiveness to the Neurons in Recurrent Neural Networks," ECCV 2018.
[16] Baddar et al., "Mode Variational LSTM Robust to Unseen Modes of Variation: Application to Facial Expression Recognition," AAAI 2019.

