Leveraging the Generalization Ability of Deep Convolutional Neural Networks for Improving Classifiers for Color Fundus Photographs
This paper proposes a confidence-based noisy label filtering combined with pseudo-labeling SSL, demonstrating strong performance on noisy data and rare positive case detection, ultimately achieving an AUROC of 0.9993 on the off-site validation set.

작성자
AI Research Team | Jae Young Kim
Original Paper
Author Contributions
Author Contributions: Conceptualization, J.S., J.K. and S.T.K.;Formal Analysis, J.S. and J.K.; Methodology, J.S., J.K., S.T.K. and K.-H.J.; Writing—Original draft, J.S., J.K. and S.T.K.; Writing—Review & Editing, J.S. and K.-H.J.; Supervision, K.-H.J. All authors have read and agreed to the published version of the manuscript.
Introduction
Deep neural networks (DNNs) achieve their advanced performance through supervised learning, which requires a large amount of annotated data. The annotation task is often crowdsourced for economic efficiency, but the dataset annotated by non-experts with limited supervision may contain inaccurate labels. Noisy labels not only yield DNNs with sub-optimal performance but may also impede their optimization dynamics. Furthermore, since acquiring samples for minor classes is inherently difficult or time-consuming, real-world data often exhibit long-tailed distribution. Therefore, when applying the deep learning (DL) algorithms to practical application, handling those challenges plays a crucial role in the robustness of DNNs.
My team proposed a method to address the aforementioned problems and participated in the pathological myopia classification challenge (PALM) competition held at MICCAI, top conference for medical image processing, and won first place in classification challenge. This post introduces various practical techniques covered in the competition and please refer to the paper for more detailed information.
Although the proposed method has been applied to medical images that are different from the areas covered by the Genesis Lab, we believe that this post is meaningful because the proposed method can be extended to other domains.
Dataset
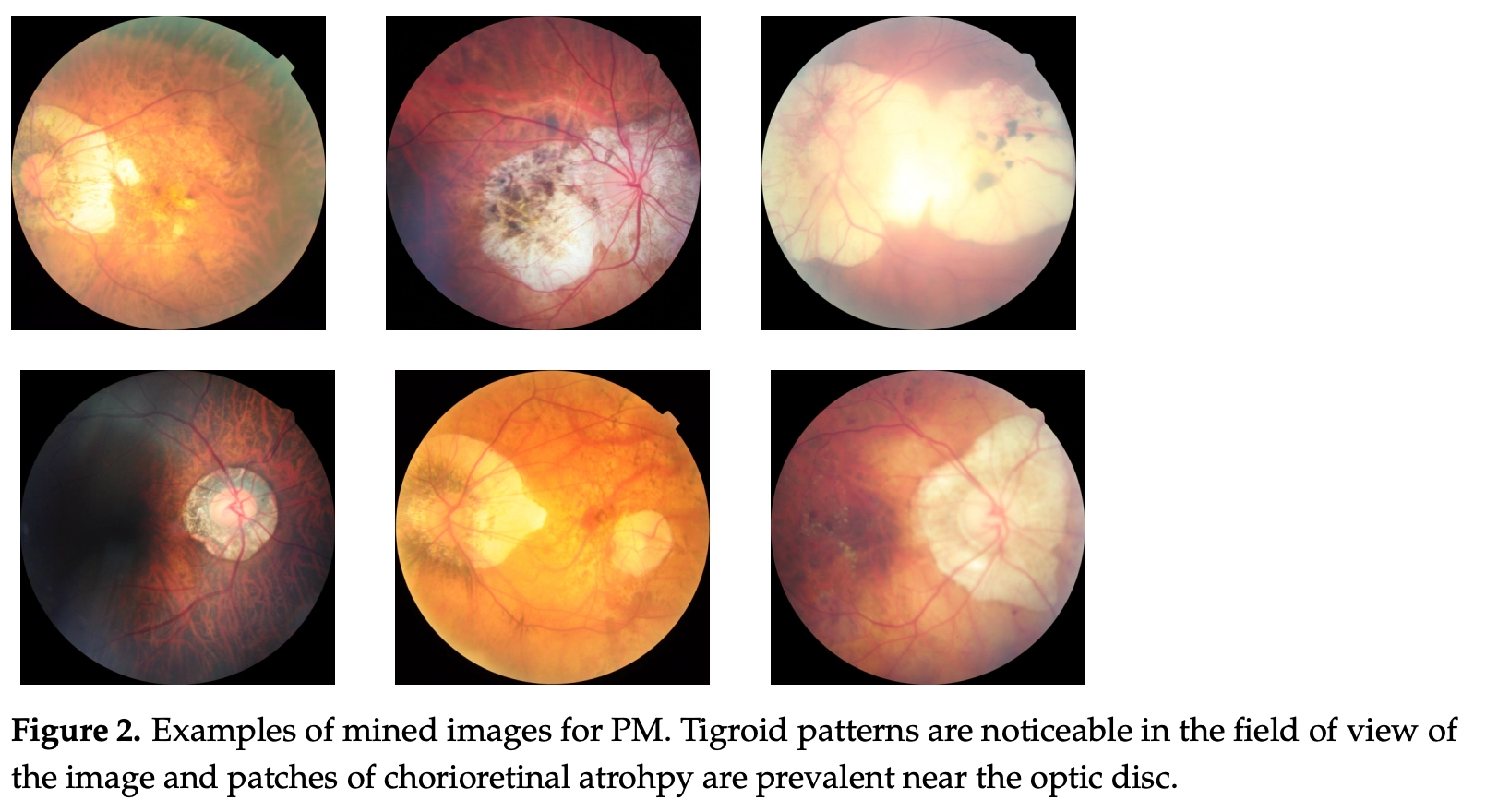
Fundus photographs were used in order to classify Pathological myopia (PM), and the images above are examples of fundus images in which PM occurred. PM could be diagnosed due to other clinical evidence such as retinal detachment or characteristics of tigroid patterns. PM typically occurs in 0.9–3.1% among Asian ethnicities and 1.2% among Australian ethnicities. In contrast to standard deep learning (DL) datasets with millions of annotated samples, the PALM dataset is far smaller with only 400 data and consists of even far fewer positive cases.
Method
In PALM competition, two main methods were used to improve the generalization ability of DNNs:
- the use of semi-supervised learning (SSL) using unlabeled samples
- the design of filtration network that detect clean positive data to reduce the effect of noisy dataset; the network serves to identify mislabeled cases in the training set.
Leveraging the Generalization Ability of DNNs for pseudo-labeling
One of the ways to compensate for the lack of data is SSL using unlabeled data, among which pseudo-labeling is a method proven to be effective in many studies. However, the existing pseudo-labeling procedure typically deals with cases with balanced distributions between classes and thus, when pseudo-labels are generated by a model trained in a long-tailed distribution dataset, the artificial labels are inaccurate for minor classes. Therefore, in order to obtain a more accurate pseudo-label, we hypothesize as follows, by considering the prior knowledge of the domain and generalization ability:
- Since the rate at which pathological myopia (PM) usually occurs is 0.9–3.1%, the number of PM cases in public fundus images would not outnumber that of normal cases unless it was a PM dataset.
- At the beginning of training, DNNs first learn the general feature of a dataset, even in the presence of noises, and memorization follows as the training progresses.
Based on the above hypotheses, unlabeled public dataset was collected and ‘normal’ class was assigned to all the unlabeled images, then incorporating both the public dataset and the PALM dataset. It leads to noises, however, as all the labels in the public dataset have been assumed to be ‘normal,’ but a method of utilizing predictions made in the initial training is used to generate pseudo-labeling for the public dataset. It was then re-trained from scratch using this artificially annotated public dataset and validated using the PALM dataset. A total of 91,509 unlabeled fundus images were acquired from publicly available datasets Kaggle [1], Messidor [2], IDRiD [3], REFUGE [4], and RIGA [5].
Filtering Suspicious Data
To reduce the negative effect of noisy dataset, filtration networks detecting clean positive data had been designed and clean data identified from filtration networks $b$ were included in PM classification model $f \rightarrow \hat{p}\in\Delta(\mathbb{y})$ training.
$b$ detects clean positive data using posterior distribution of $D_{val}$ and $f$. The training of filtration networks $b$ is trained at each validation step and takes a posterior distribution $\hat{p}$ of $f$ as an input. Optimizing $b$ is done by minimizing errors between output of $b$ and $y_{val}$. Because the filtration network was trained on data with clean labels, a well-trained filtration network would identify clean positive data by predicting high values on positive images with clean labels and predicting low values for suspiciously negative images. As $b^*$ is trained at each validation step (one training epoch), logistic regression model ($b(\hat{p})=w^T\hat{p}$) is used for training time efficiency. Consequently, if $b^*$ detect the clean data with higher confidence than $\tau$ for train samples $D_{train}$, the data contribute to the training of $f$.:
$\theta_f = \theta_f - \eta \nabla L(\theta_f;x,y)\mathbf{1}\{b^*(\hat{p})>\tau\}$
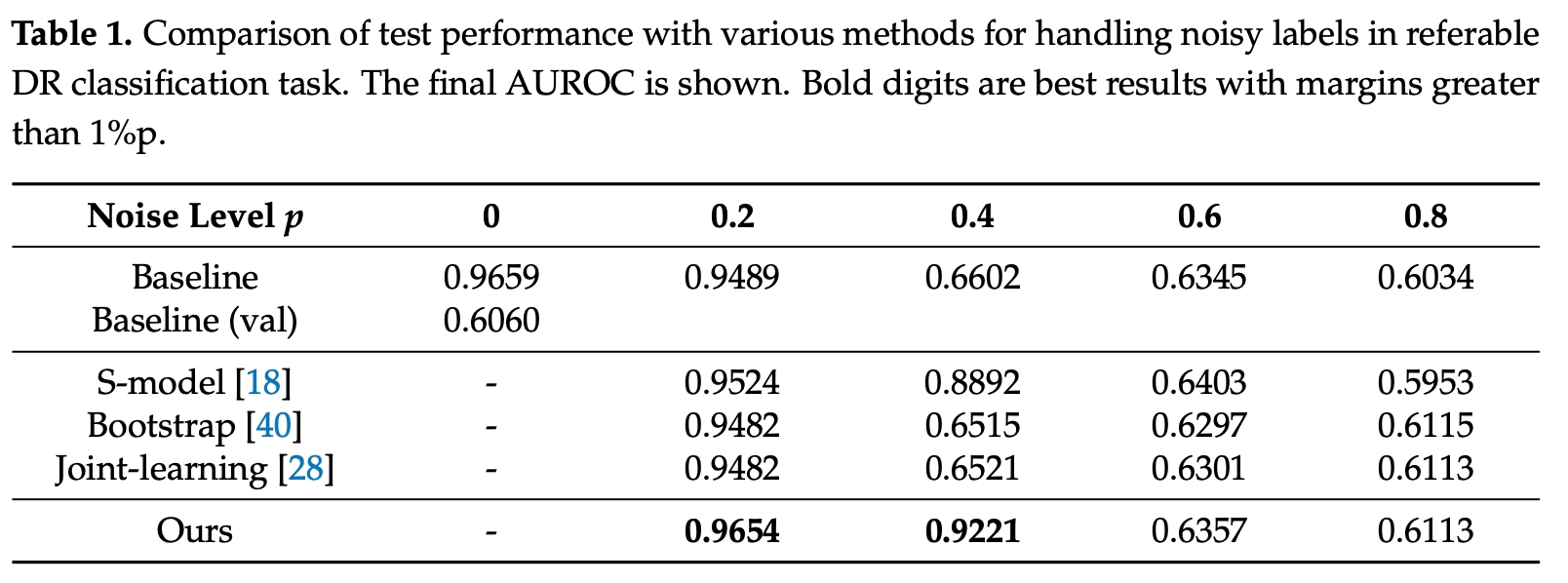
To verify the validity of the filtration network, quantitative results were compared with those of existing state-of-the-art methods using Kaggle 2015 dataset with 35,126 images (17,563 eyes) for training and 53,576 images (26,788 eyes), and the proposed method achieved the highest accuracy in p < 0.5(Table 1).
Conclusion
On this post, we present a method for filtering noisy labels based on the classifier’s confidence and SSL based on pseudo-labels using publicly-available unlabeled data. Our noisy label filtration method outperformed existing methods in the presence of noisy data, and the pseudo-labeling procedure using generalization ability of DNNs was effective in identifying rare positive cases, having achieved high performance by enabling unfamiliar patterns to be trained, a difficulty in original small training set. In the end, we attained an AUROC of 0.9993 on the PALM competition, ranking first on the off-site validation set.
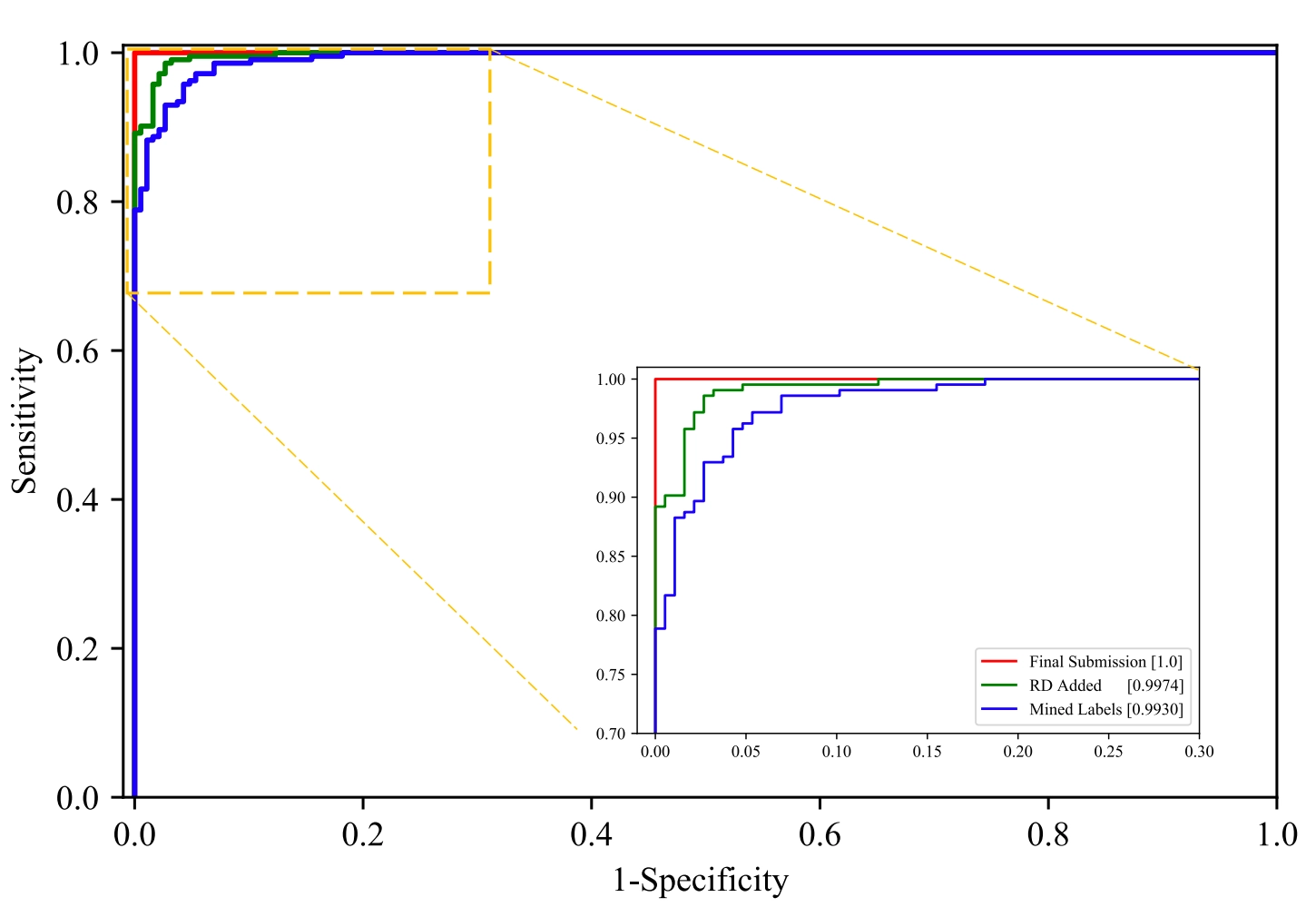
The approach proposed on the PALM competition was applied to medical data, but we expect it to be applicable in various real-world settings that require a large volume of labeled data.
References
[1] Kaggle, "Diabetic Retinopathy Detection Competition Report," Kaggle 2015.
[2] Decencière et al., "Feedback on a Publicly Distributed Database: The Messidor Database," Image Anal. Stereol. 2014.
[3] Porwal et al., "Indian Diabetic Retinopathy Image Dataset (IDRiD): A Database for Diabetic Retinopathy Screening Research," Data 2018.
[4] "Retinal Fundus Glaucoma Challenge," REFUGE Grand Challenge 2019.
[5] Almazroa et al., "Retinal Fundus Images for Glaucoma Analysis: The RIGA Dataset," SPIE Medical Imaging 2018.

