Lightweight and Effective Facial Landmark Detection using Adversarial Learning with Face Geometric Map Generative Network
This paper demonstrates that adversarial training with facial geometric information effectively improves FLD performance, and presents a simple yet effective architecture that enables landmark extraction using only the encoder at test time.

작성자
AI Research Team | Seok Kyu Choi
Original Paper
Facial Landmarks are features that represent key elements that make up a face (eyes, eyebrows, nose, mouth, and jawline). There are usually 68 feature points and they are used to find faces inside of an image. This is why Facial Landmark Detection is very important when trying to find faces elaborately. The facial landmarks detected through the algorithm is used not only to detect faces but also in various fields of computer vision, such as head posture estimation and emotion recognition.
Facial Landmark
Facial Landmarks are features that represent key elements that make up a face (eyes, eyebrows, nose, mouth, and jawline). There are usually 68 feature points and they are used to find faces inside of an image. This is why Facial Landmark Detection is very important when trying to find faces elaborately. The facial landmarks detected through the algorithm is used not only to detect faces but also in various fields of computer vision, such as head posture estimation and emotion recognition.

Introduction
Facial Landmark Detection is a task of localizing facial key components which provide essential information for computer vision task. In general, there are two FLD methods. Optimization-based methods, which predicts directional movement to fit the facial model to the given face image, and regression-based methods, where it directly predicts the position of a landmark point using learned parameters. Recently, deep learning-based methods have shown better performances. There have been numerous new studies on different methods, as deep learning-based research grows in popularity, such as the multi-task learning method which tries to simultaneously solve tasks such as face detection and head pose estimation. The facial landmark detection research must be applicable to mobile or web applications, so the model needs to be simple as well as accurate. However, when using a simple CNN structure, the performance from images with misaligned facial contour is not that satisfying. A study using two sub-networks that predicts the inner components and the contour of the face each, alleviated the problem — but still hard to say that it is solved.
This paper proposes a Geometric Prior-Generative Adversarial Network based on GAN that learns through adversarial mini-max game between generator and discriminator. The proposed model uses adversarial and face geometric loss to train, unlike conventional methods that just use L1 or L2 loss to learn the difference between ground truth facial landmarks and predicted landmarks. In the paper, a generator is trained to predict the facial inner geometric map and facial contour geometric map, through the output value of the trained Encoder, which is trained to predict the coordinates of the face landmark from the face image. In addition, the Discriminators are designed to learn to distinguish between ground truth facial landmarks and a predicted facial landmarks by a generating model.
Face Geometry Generative Adversarial Network
Model Overview
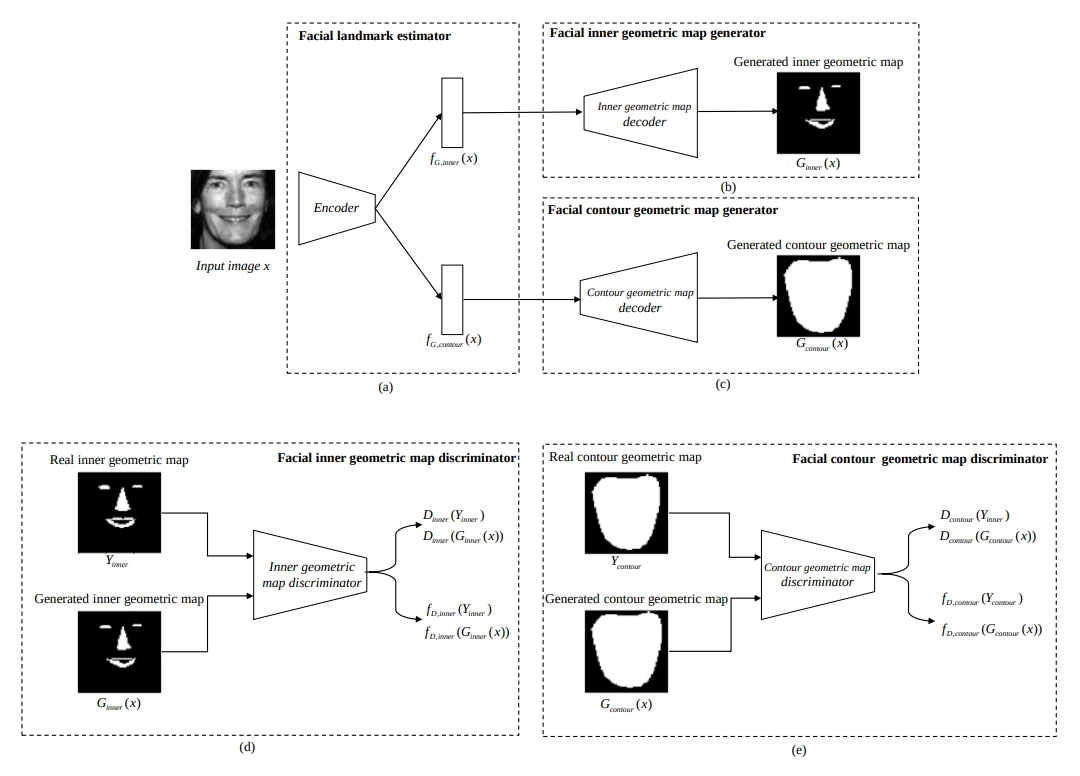
Training Face Geometric Map Generator
The generator composed of one encoder that predicts facial inner and contour landmarks from an input image, and two decoders that generate a geometric map from the output values of the encoder. The geometric face features are vital to accurately predict landmarks for images containing various noise, such as cropped or angled faces. The previous method, the L1 and L2 method that only considers the difference between the actual and predicted values, does not take these features into account. However, in this paper, the encoder in the generator predicts the inner face and contour landmarks respectively, and the decoder in the generator utilizes them to create a geometric map. When training the generator, the adversarial loss function and the prediction loss function of the discriminator is also taken into account, but the discriminator’s parameters are fixed.
Training Discriminator
Each discriminator is trained to determine whether the inputted geometric map is real or generated, and to predict facial landmark as well. The loss function that is calculated during the training of generators is included in among the discriminator loss functions. The generator is trained to generate more realistic geometric maps, since the parameters of the discriminant function are not updated during generator training, in order to minimize loss. Similarly, the generator parameters are fixed during the discriminator training.
Experiement Result
| Name | Train | Test | Argumentation Data |
|---|---|---|---|
| HELEN DATASET | 2,000 | 330 | 24,000 |
| 300-W DATASET | 3,148 | 689 | 40,082 |
The datasets used in the experiment are HELEN and 300-W. HELEN has two types of annotations: one is 194 landmarks and the other is 68 landmarks. 300-W consists of 4 subsets ( AFW,LFPW,HELEN,IBUG), 3,148 training data (AFW:377+,HELEN:2,000+LFPW:811), 689 test data(LFPW:224+,HELEN:300+,IBUG:135). Also, data augmentation such as translation, rotation, and magnifications were conducted.
Experiments for Performance Comparison
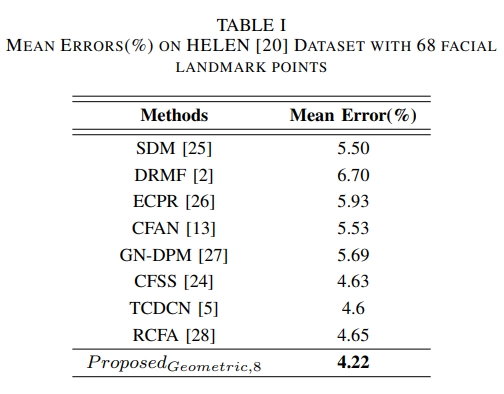
If you look at the table above, you can see that it performs better than the existing methods. It performs better than TCDCN which was pretrained through MAFL Database, and RCFA that uses RNN for face alignment.
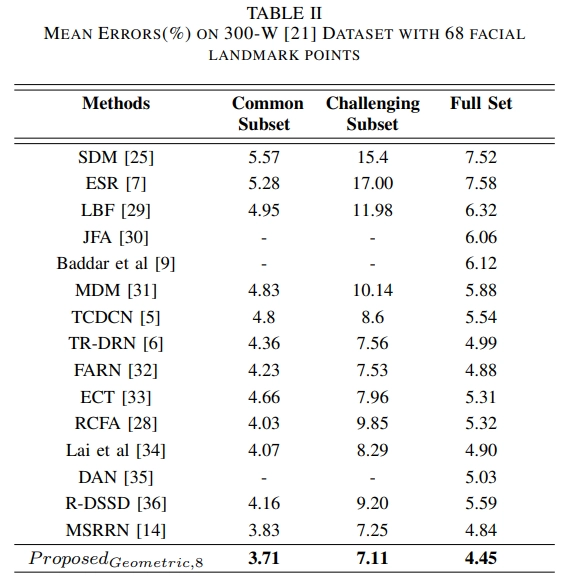
In the table above, the model proposed by this paper shows the best performance even in the 300-W, which contains extremely challenging images, so it could be considered to be more robust than other models.
Experiment Results for Usefulness of Contour Map
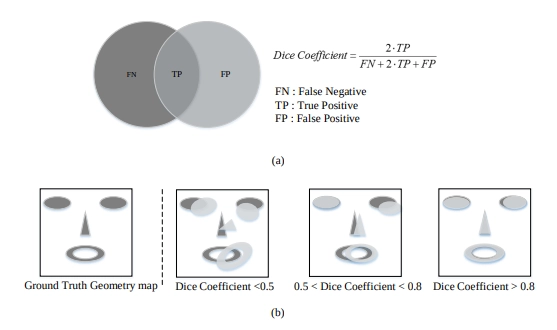
In this paper, they verified the effectiveness of contour geometric maps through experiments.
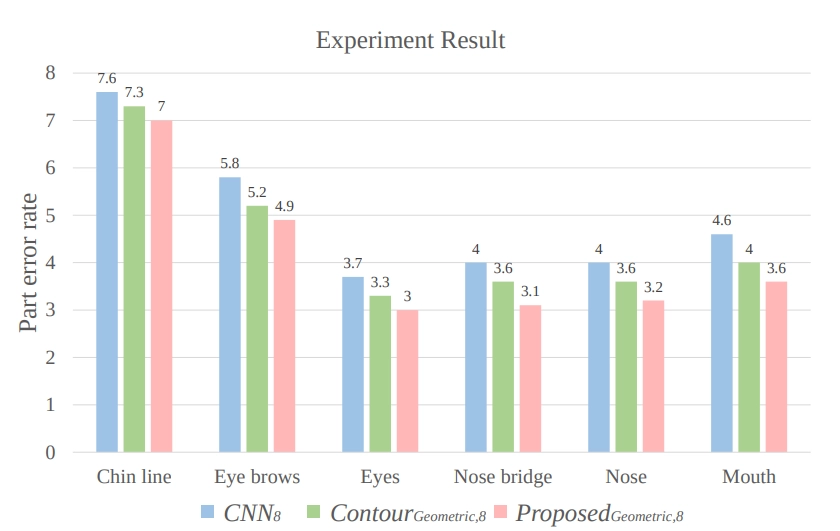
The graph above is an experiment with three models, which have the same structure but different training methods. CNN8 is a model optimized with L1 and Contour Geometric,8 is a model trained without Facial Inners considered. As the experiment result above shows, the method using facial contour performs better than the one using the general L1 loss method, and this is further improved when facial inners are used.
Conclusion
This paper presented that adversarial learning using geometric facial information is better than existing methods in FLD. The facial contour geometric map helps inner facial landmark points to be localized within the correct facial contour region. During the test stage, the landmarks could be extracted using the encoder only, so it has achieved the goal of being a simple yet effective FLD network that can be applied to various applications.
References
[2] Asthana et al., "Robust Discriminative Response Map Fitting with Constrained Local Models," CVPR 2013.
[5] Zhang et al., "Learning Deep Representation for Face Alignment with Auxiliary Attributes," IEEE TPAMI 2016.
[6] Lv et al., "A Deep Regression Architecture with Two-Stage Re-initialization for High Performance Facial Landmark Detection," CVPR 2017.
[7] Cao et al., "Face Alignment by Explicit Shape Regression," IJCV 2014.
[13] Zhang et al., "Coarse-to-Fine Auto-Encoder Networks (CFAN) for Real-Time Face Alignment," ECCV 2014.
[14] Wang et al., "Multiscale Recurrent Regression Networks for Face Alignment," Applied Informatics 2017.
[24] Zhu et al., "Face Alignment by Coarse-to-Fine Shape Searching," CVPR 2015.
[25] Xiong et al., "Supervised Descent Method and Its Applications to Face Alignment," CVPR 2013.
[26] Burgos-Artizzu et al., "Robust Face Landmark Estimation under Occlusion," ICCV 2013.
[27] Tzimiropoulos et al., "Gauss-Newton Deformable Part Models for Face Alignment In-the-Wild," CVPR 2014.
[28] Wang et al., "Recurrent Convolutional Face Alignment," ACCV 2016.
[29] Ren et al., "Face Alignment at 3000 FPS via Regressing Local Binary Features," CVPR 2014.
[30] Xu et al., "Joint Head Pose Estimation and Face Alignment Framework Using Global and Local CNN Features," IEEE FG 2017.
[31] Trigeorgis et al., "Mnemonic Descent Method: A Recurrent Process Applied for End-to-End Face Alignment," CVPR 2016.
[32] Hou et al., "Face Alignment Recurrent Network," Pattern Recognition 2018.
[33] Zhang et al., "Combining Data-Driven and Model-Driven Methods for Robust Facial Landmark Detection," IEEE TIFS 2018.
[34] Lai et al., "Deep Recurrent Regression for Facial Landmark Detection," IEEE TCSVT 2016.
[35] Kowalski et al., "Deep Alignment Network: A Convolutional Neural Network for Robust Face Alignment," CVPRW 2017.
[36] Liu et al., "Learning Deep Sharable and Structural Detectors for Face Alignment," IEEE TIP 2017.

